参考链接:
https://blog.csdn.net/m0_51246873/article/details/127167749
https://www.cnblogs.com/YenKoc/p/14136012.html
https://www.xjx100.cn/news/40167.html?action=onClick
https://mp.weixin.qq.com/s/MUth1Qw-Fl2a5OrLw_2_0g
常见指令
0xE8 call + 4字节偏移地址
0xE9 jmp + 4字节偏移地址
0xEB jmp + 2字节偏移地址
0xFF15 call + 4字节地址
0xFF25 jmp + 4字节地址
0xcc int 3
0xe2 loop
0x0f84 jz
0x0f85 jnz
一、什么是花指令 1)定义 花指令又名垃圾代码、脏字节,英文名是junk code。花指令就是在不影响程序运行的情况下,往真实代码中插入一些垃圾代码,从而影响反汇编器的正常运行;或是起到干扰逆向分析人员的静态分析,增加分析难度和分析时间。
2)分类 花指令分为不可执行花指令、可执行花指令
可执行花指令 顾名思义,可以执行的花指令,这部分垃圾代码会在程序运行的时候执行,但是执行这些指令没有任何意义,并不会改变寄存器的值,同时反汇编器也可以正常的反汇编这些指令。目的是为了增加静态分析的难度,加大逆向分析人员的工作量。
不可执行花指令 不可以执行的花指令,这类花指令会使反编译器在反编译的时候出错,反汇编器可能错误的反汇编这些指令。根据反汇编的工作原理,只有花指令同正常指令的前几个字节被反汇编器识别成一组无用字节时,才能破坏反汇编的结果。因此,插入的花指令应当是一些不完整的指令,被插入的不完整指令可以是随机选择的。
为了能够有效迷惑反汇编器,同时又确保代码的正确运行,花指令必须满足两个基本特征,即:
垃圾数据必须是某个合法指令的一部分。
程序运行时,花指令必须位于实际不可执行的代码路径。
3)原理:反汇编算法的设计缺陷 常用的两类反汇编算法: 1.线性扫描算法:逐行反汇编(无法将数据和内容进行区分) 2.递归行进算法:按照代码可能的执行顺序进行反汇编程序。 通过构造必然条件或者互补条件,使得反汇编出错。
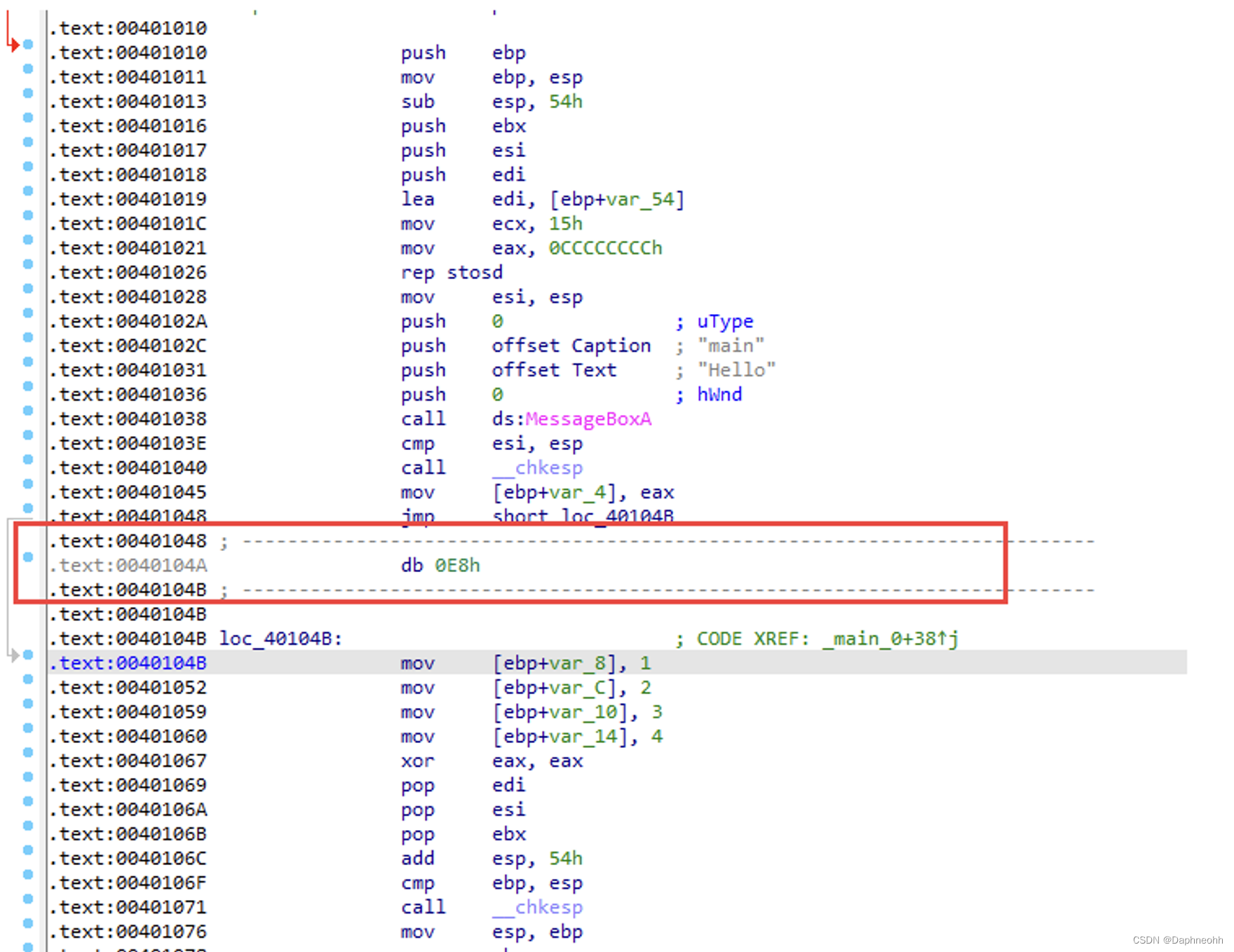
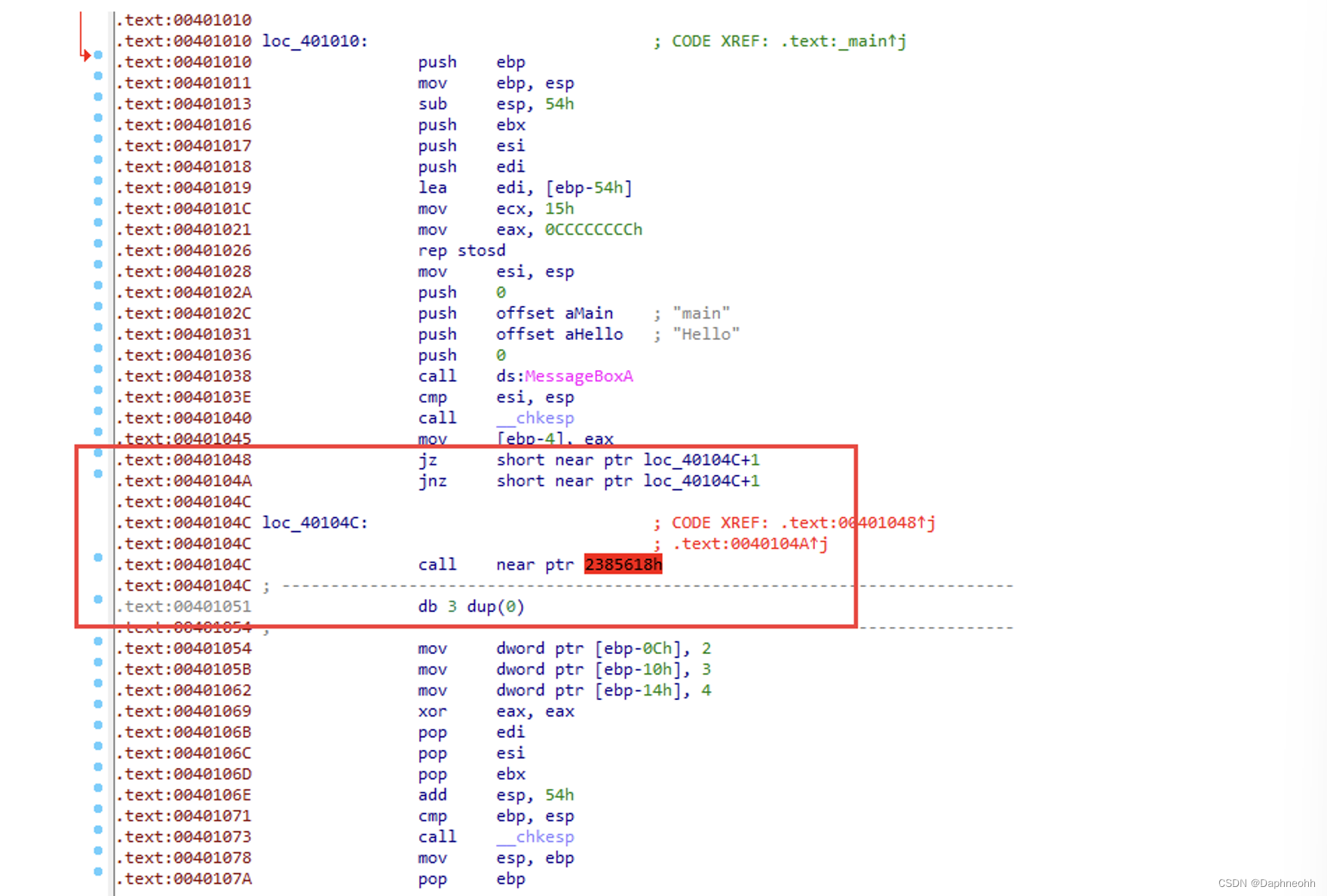
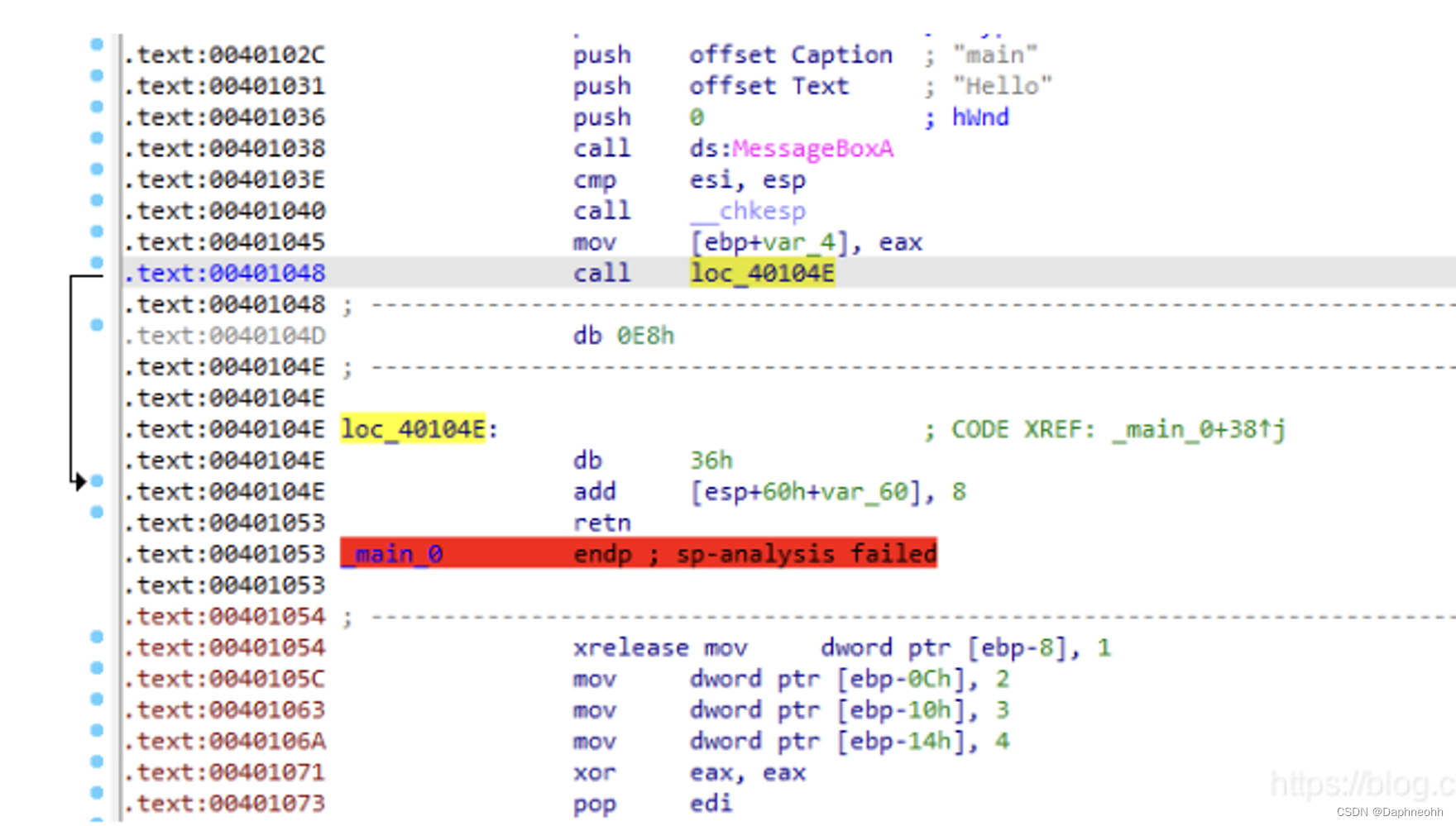
简单的花指令 0xe8是跳转指令,可以对线性扫描算法进行干扰,但是递归扫描算法可以正常分析。
两个跳转一个指向无效数据,一个指向正常数据来干扰递归扫描算法。
二、花指令实现 1.简单jmp 这是最简单的花指令。
这种jmp单次跳转只能骗过线性扫描算法,会被IDA识别(递归下降)。
1 2 3 4 5 __asm{jmp label1label1:
2.多层跳转 本质上和简单跳转是一样的,只是加了几层跳转。显然无法干扰ida
1 2 3 4 5 6 7 8 9 10 start: //花指令开始label 1 label 1 :label 2 label 2 :label 3 label 3
和单次跳转一样,这种也会被IDA识别。
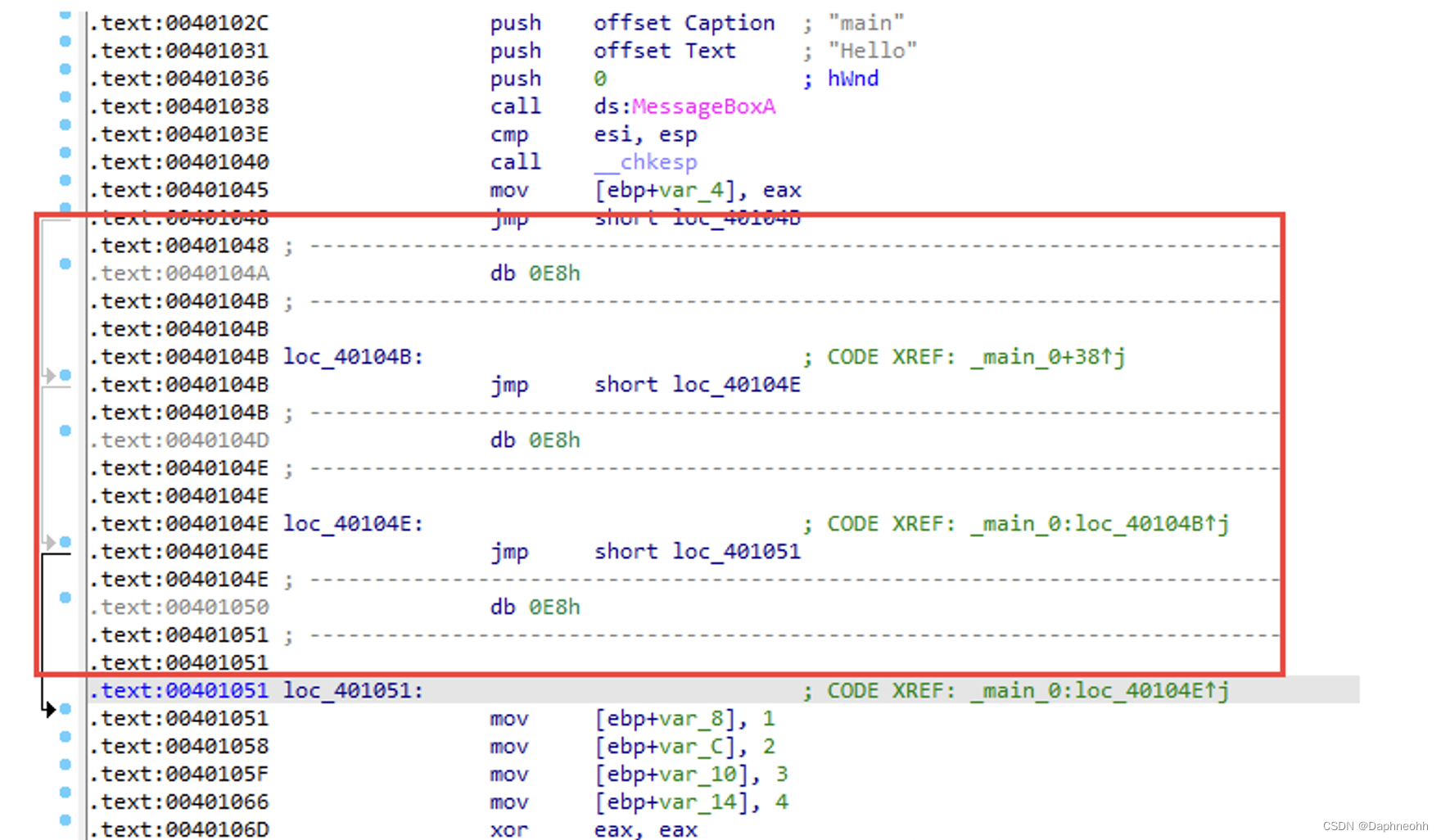
为了骗过IDA,我们将上面的花指令改写一下,
1 2 3 4 5 __asm {_emit 0 xE8_emit 0 xFF
查看反汇编后的结果
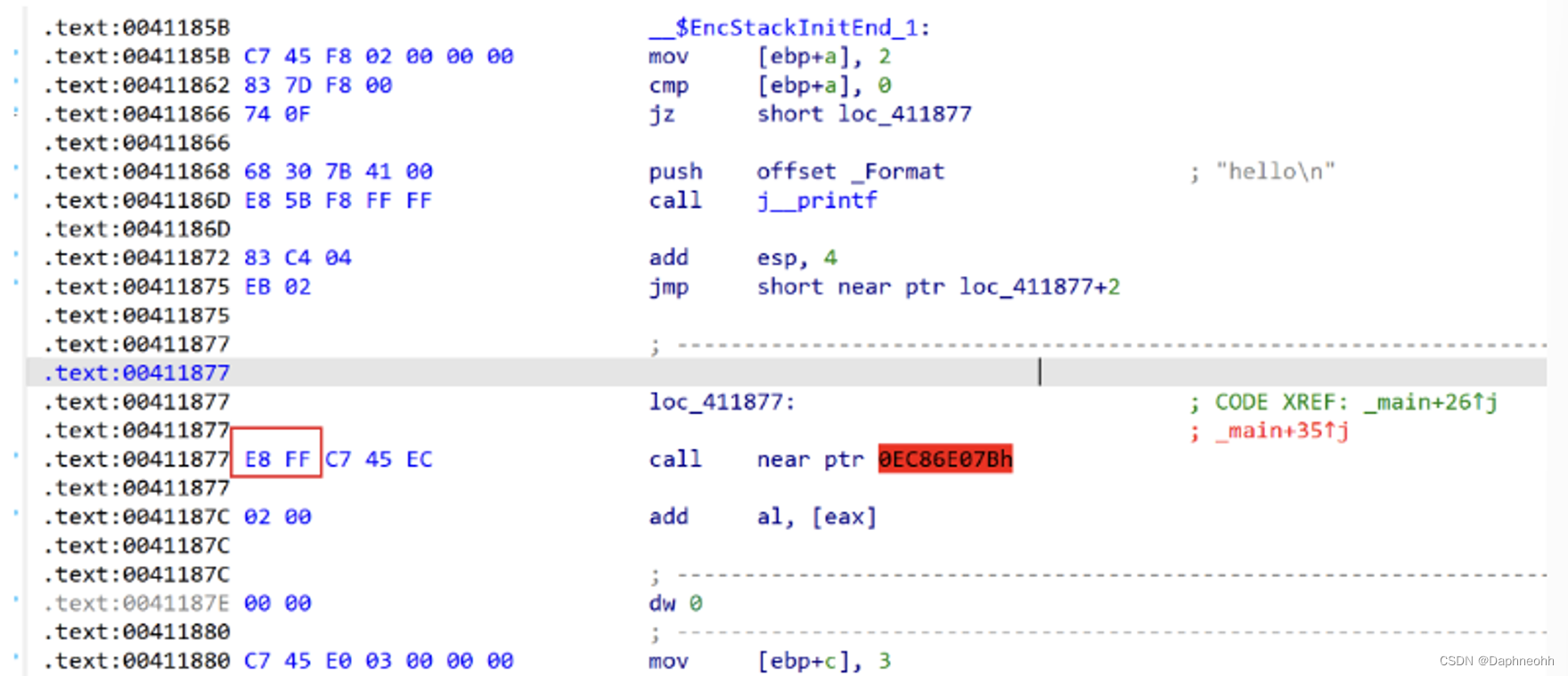
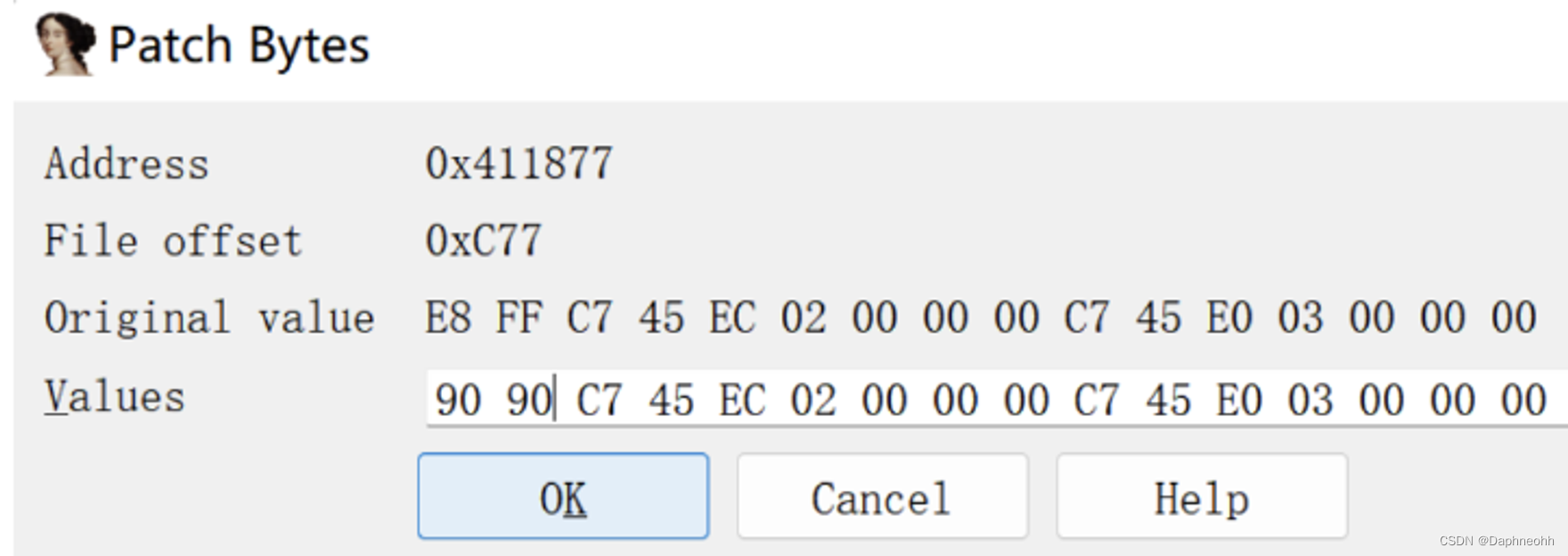
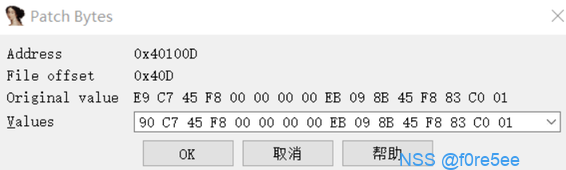
可以看到IDA错误的识别loc_411877处的代码,成功的实现了花指令的目的。那么我们知道了如何构造,自然也就明白了如何去除,只需要将插入的立即数nop掉即可,点击0xe8和0xff,点击右键,选择patching->change byte
也可以使用一个idapython脚本添加一个快捷键,
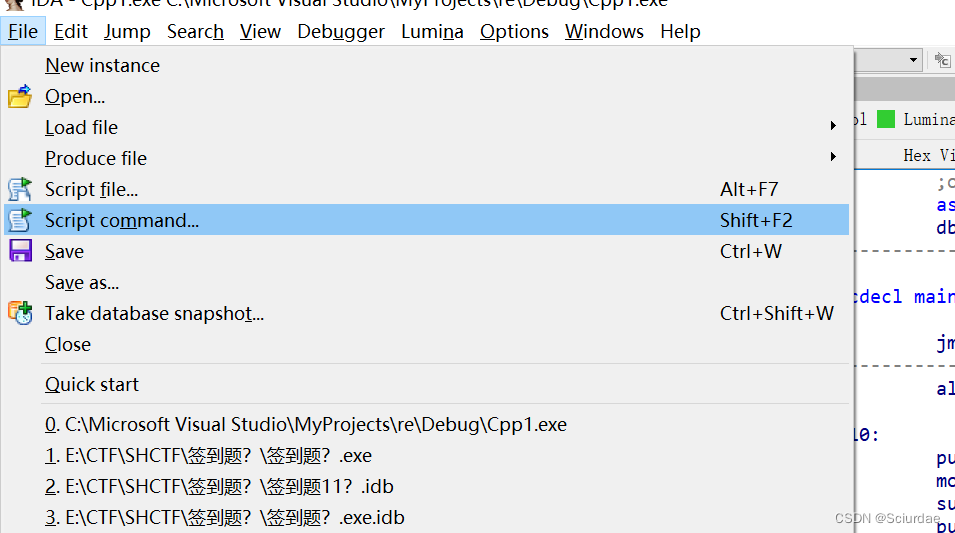
1 2 3 4 5 6 7 8 from idaapi import *from idc import *get_screen_ea ()patch_byte (start,0 x90)refresh_idaview_anyway ()add_hotkey ("ctrl-N" ,nopIt)
idapython在File - Script commannd…处 也可以Shift+F2快捷键打开
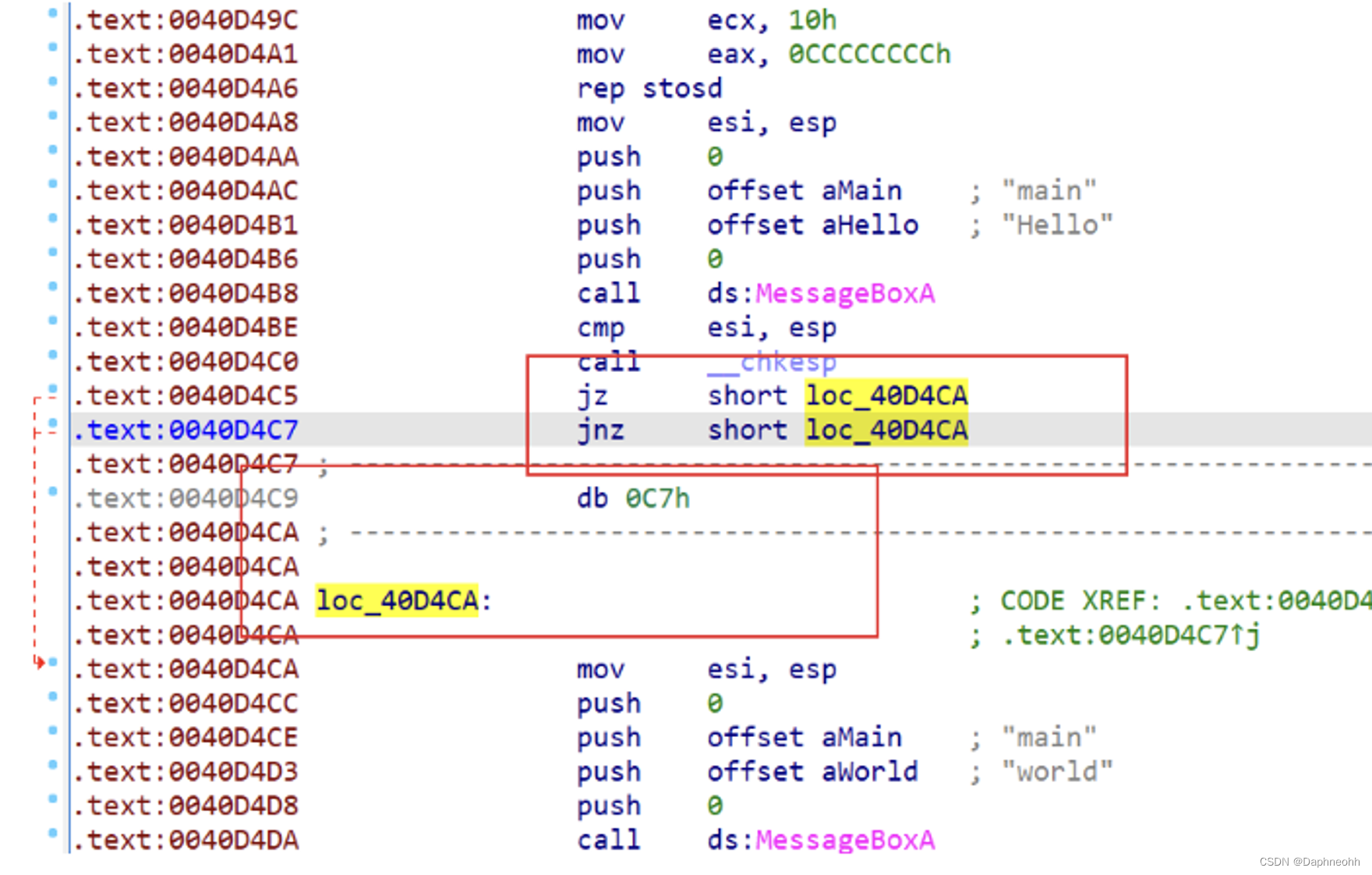
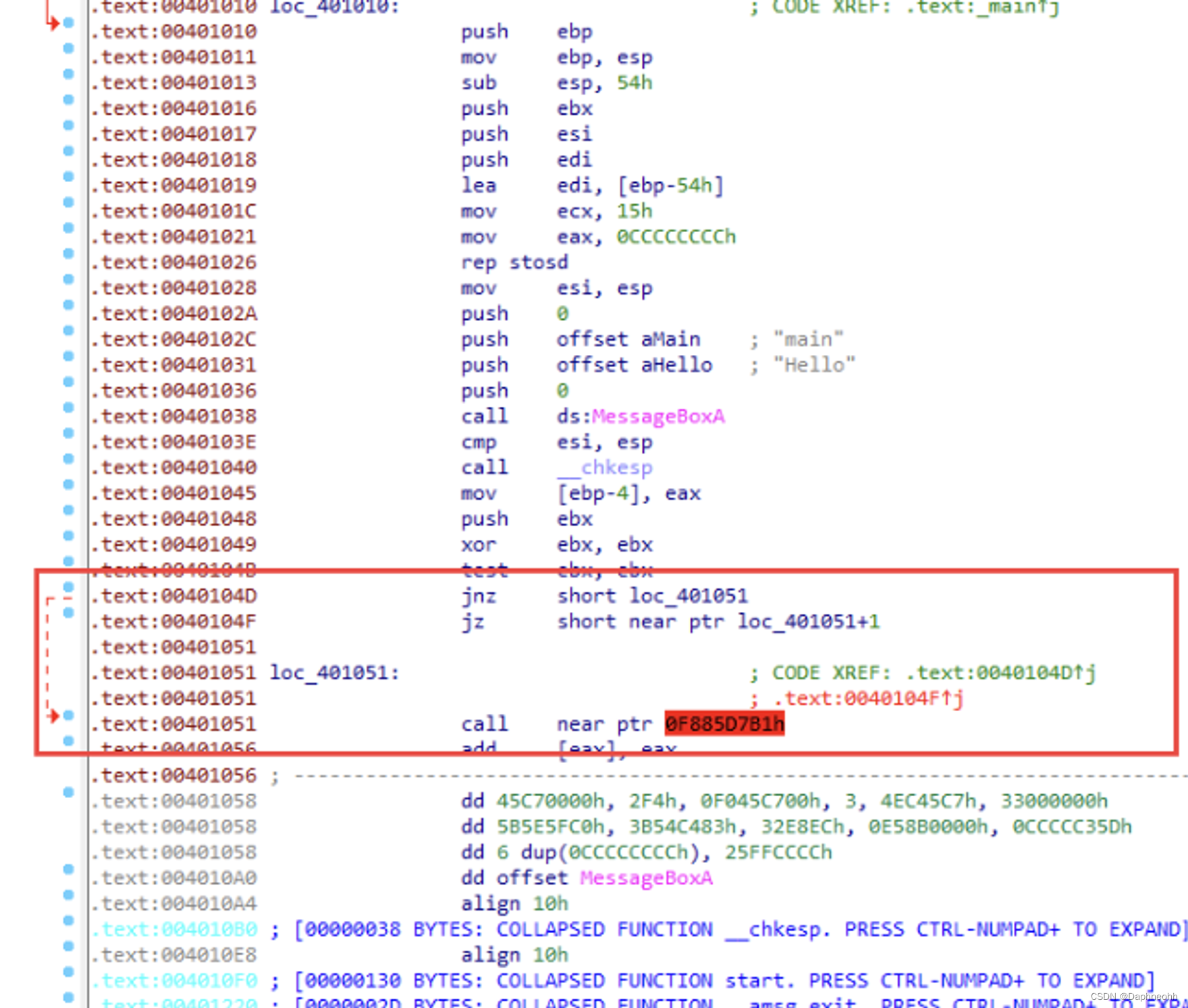
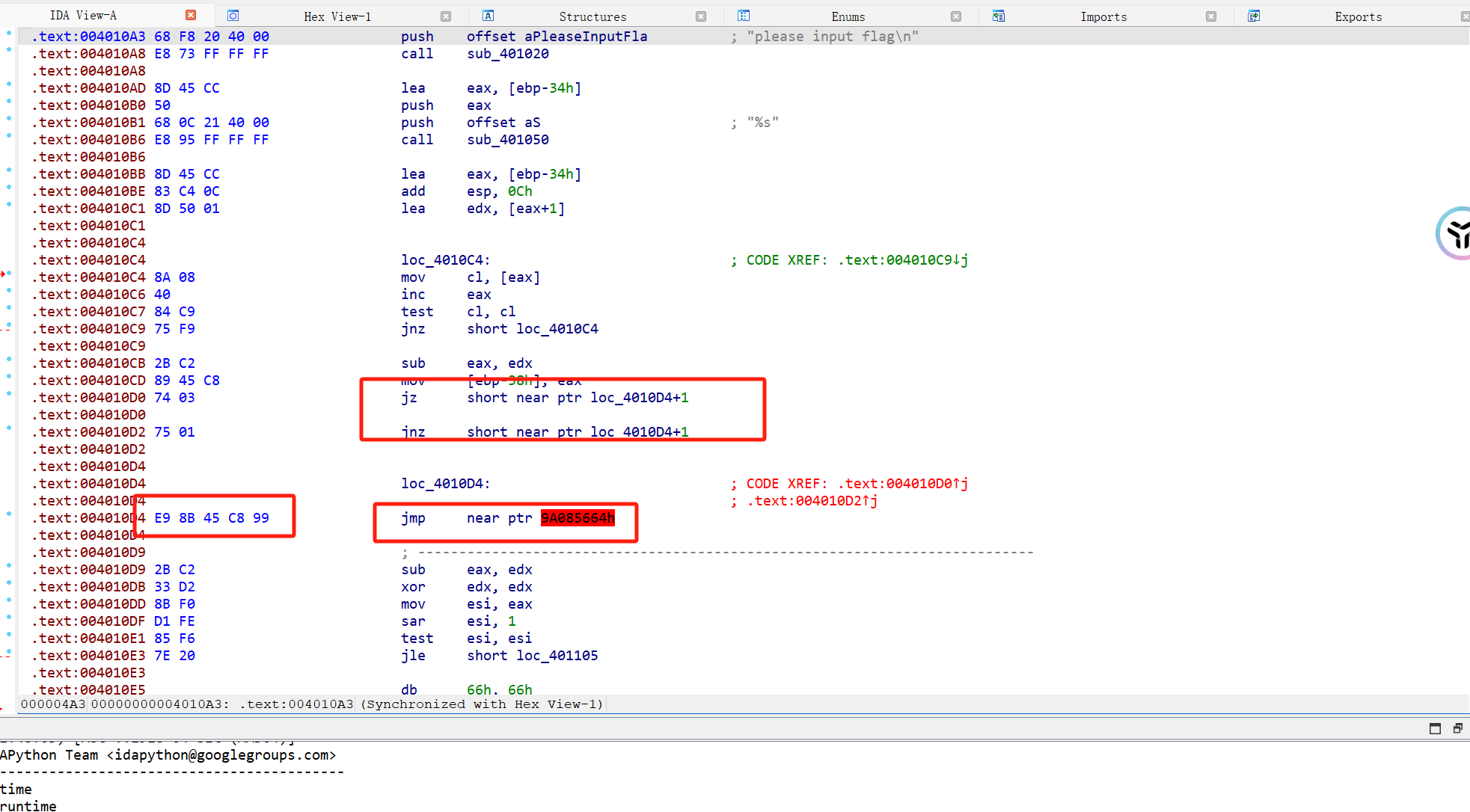
3.jz和jnz条件跳转(jz为1跳转,jnz为0跳转) 利用jz和jnz的互补条件跳转指令来代替jmp。骗过OD
1 2 3 4 5 6 _asm{label 1 label 1 label 1 :
1 2 3 4 5 __asm {Label ;Label ;0 xC7;Label :
这种混淆去除方式也很简单,特征也很明显,因为是近跳转,所以ida分析的时候会分析出jz或者jnz会跳转几个字节,这个时候我们就可得到垃圾数据的长度,将该长度字节的数据全部nop掉即可解混淆。
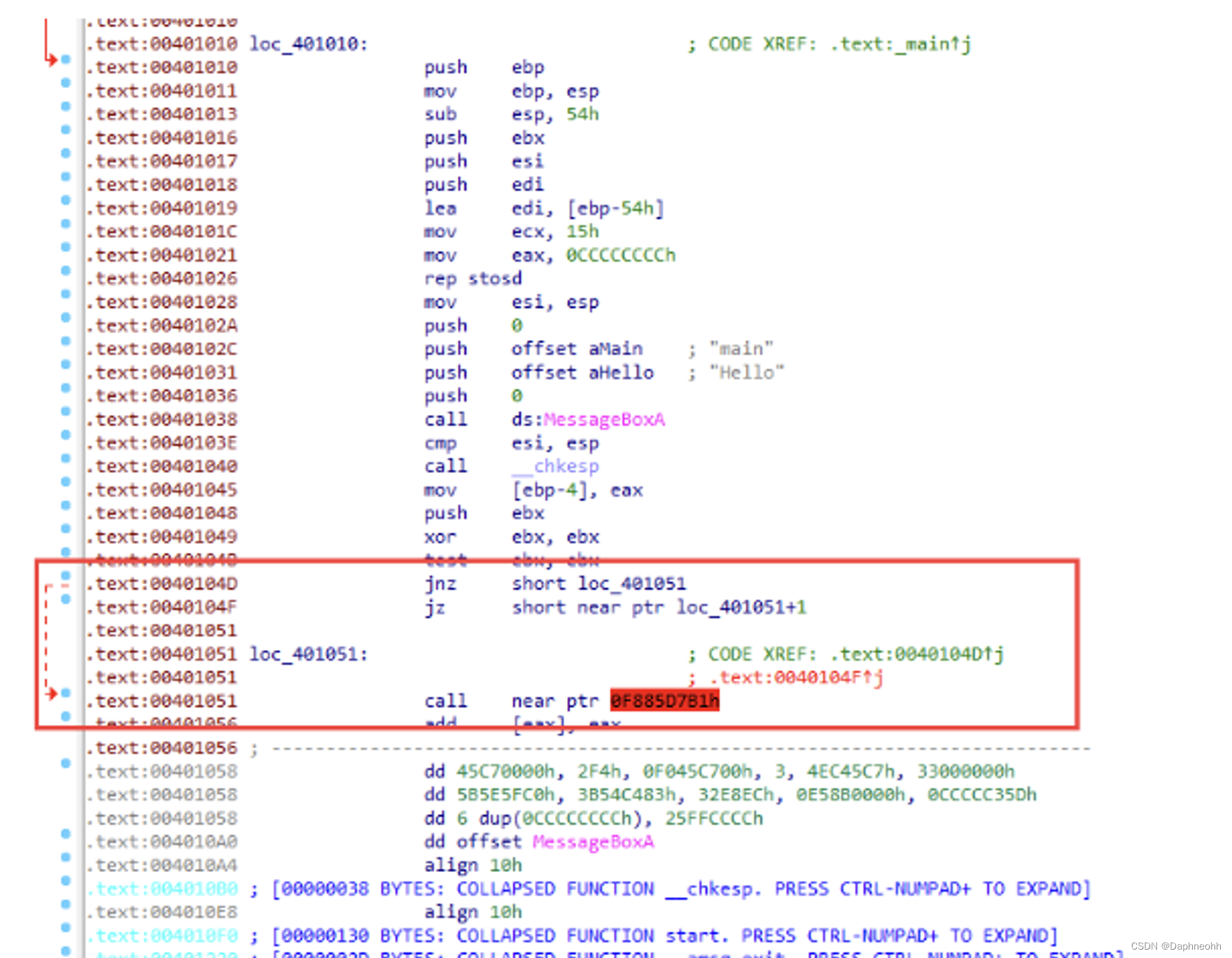
4.永真条件跳转 通过设置永真或者永假的,导致程序一定会执行,由于ida反汇编会优先反汇编接下去的部分(false分支)。也可以调用某些函数会返回确定值,来达到构造永真或永假条件。ida和OD都被骗过去了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 __asm{push ebx xor ebx ,ebx test ebx ,ebx jnz label 1 jz label 2label1: label2: pop ebx //需要恢复ebx 寄存器 clc jnz label 1:label1:
确保一个支路永远跳转
在另一个不跳转的支路填充垃圾代码
1 2 3 4 5 6 7 8 9 10 11 __asm {push ebx xor ebx , ebx test ebx , ebx jnz LABEL 7 jz LABEL 8 LABEL7: 0xC7 LABEL8: pop ebx
先对ebx进行xor之后,再进行test比较,zf标志位肯定为1,就肯定执行jz LABEL8,也就是说中间0xC7永远不会执行。
解混淆的时候也需要稍加注意,需要分析一下哪里是哪里是真正会跳到的位置,然后将垃圾数据nop掉,本质上和前面几种没什么不同。
5.call&ret构造花指令 这里利用call和ret,在函数中修改返回地址,达到跳过thunkcode到正常流程的目的。可以干扰ida的正常识别
1 2 3 4 5 6 7 8 9 10 11 __asm{call label 1 label 1 :add dword ptr ss:[esp], 8 //具体增加多少根据调试来ret call 指令:将下一条指令地址压入栈,再跳转执行ret 指令:将保存的地址取出,跳转执行
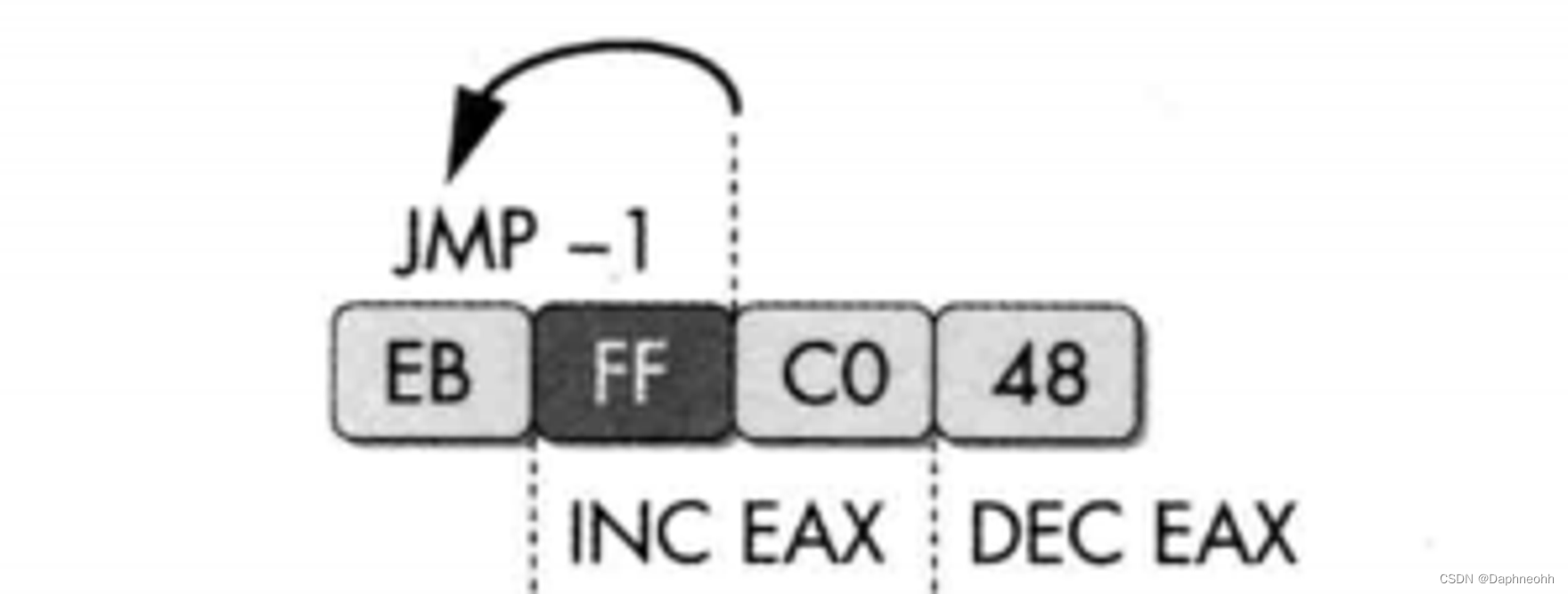
6.汇编指令共用opcode jmp的条指令是inc eax的第一个字节,inc eax和dec eax抵消影响。这种共用opcode确实比较麻烦
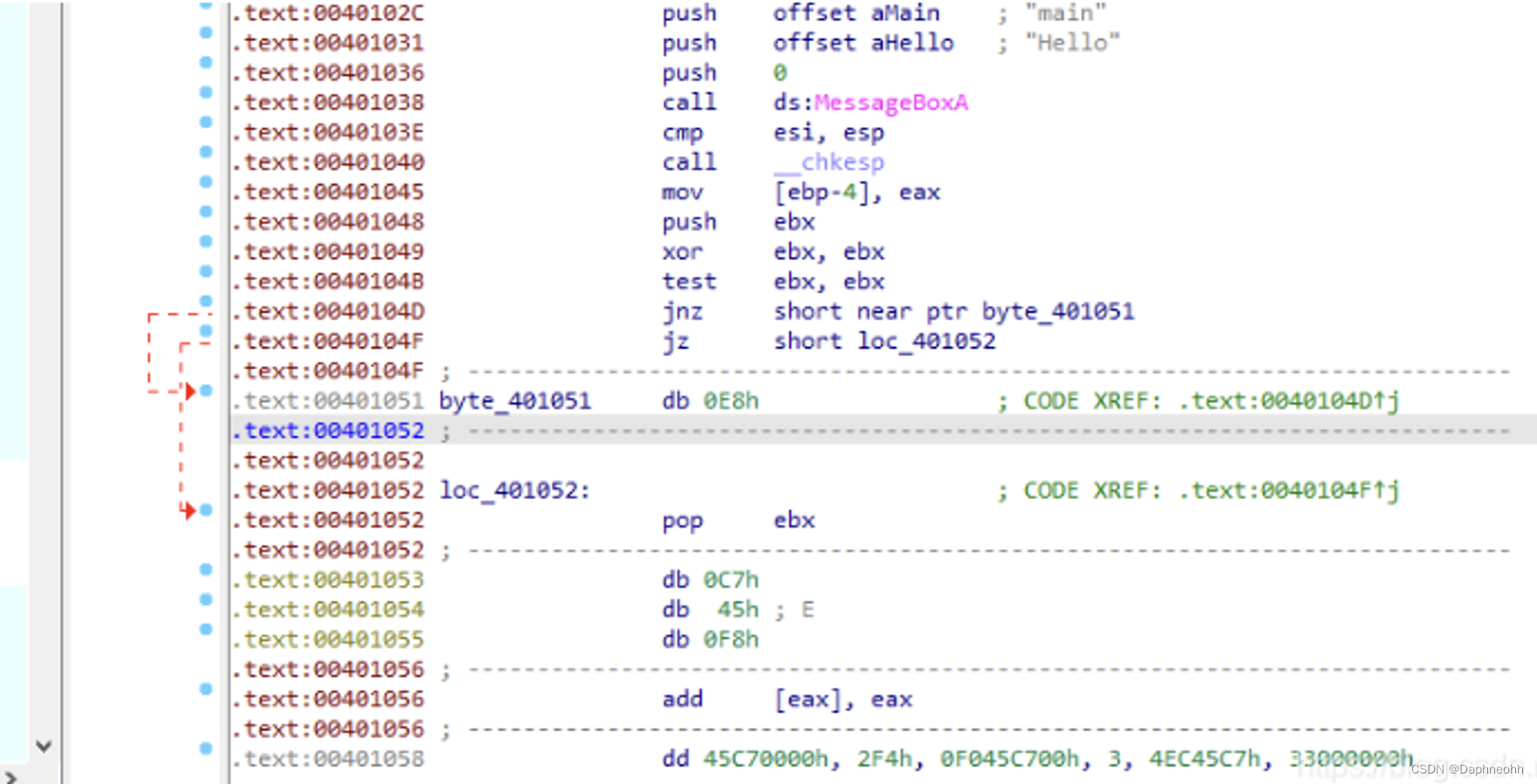
三、清除花指令 手动清除 找到所有的花指令,重新设置数据和代码地址。或者将花指令设置为nop(0x90)
在0x401051设置为数据类型(快捷键D),在0x401052设置为代码类型(快捷键C)
这里用一个ida python脚本添加ALT+N快捷键来将指令的第一个字节设置为NOP
1 2 3 4 5 6 7 8 9 from idaapi import *from idc import *get_screen_ea ()patch_byte (start,0 x90)refresh_idaview_anyway ()add_hotkey ("alt-N" ,nopIt)
参考文章
原文链接:https://blog.csdn.net/Daphneohh/article/details/139422749
快捷键 P 保存汇编代码
F5 反编译
shift+2 编写exp
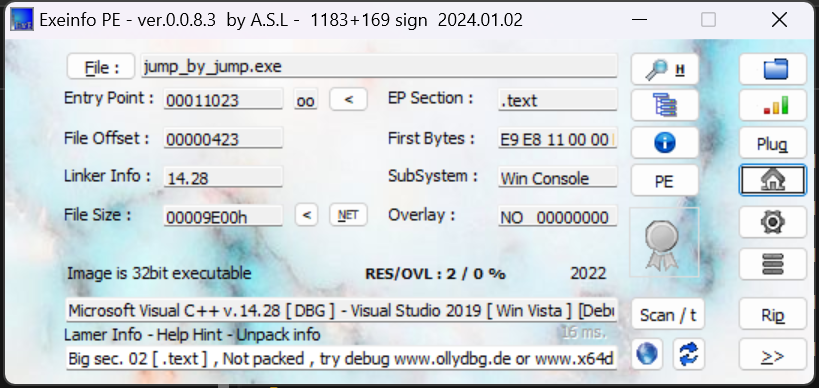
例题jmp 1、nssctf jump_by_jump 先查壳,放32位ida
看汇编
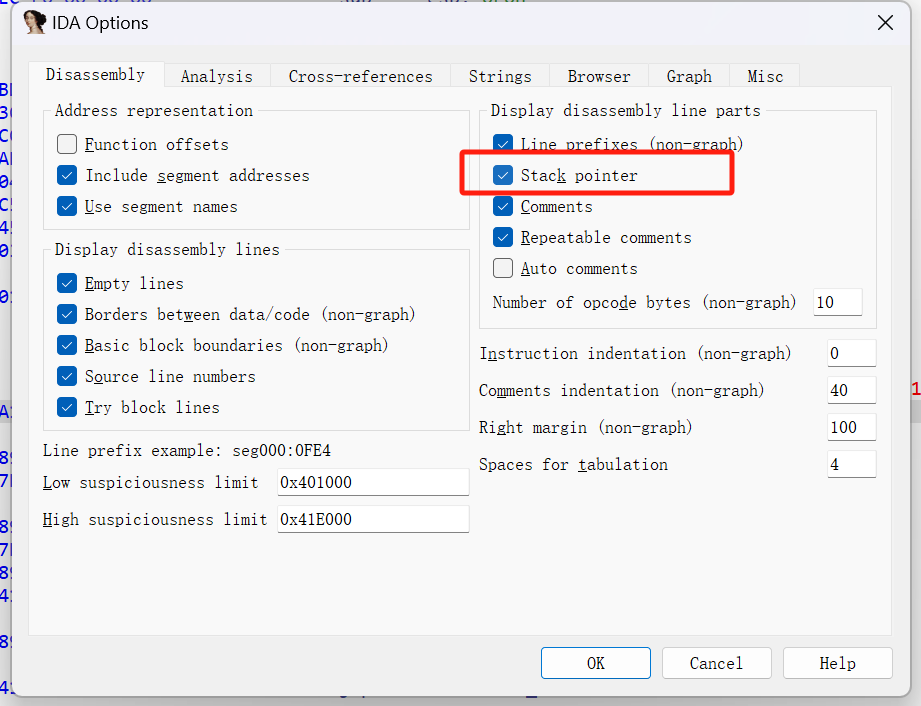
打开Options-General
可以把stack pointer打开,
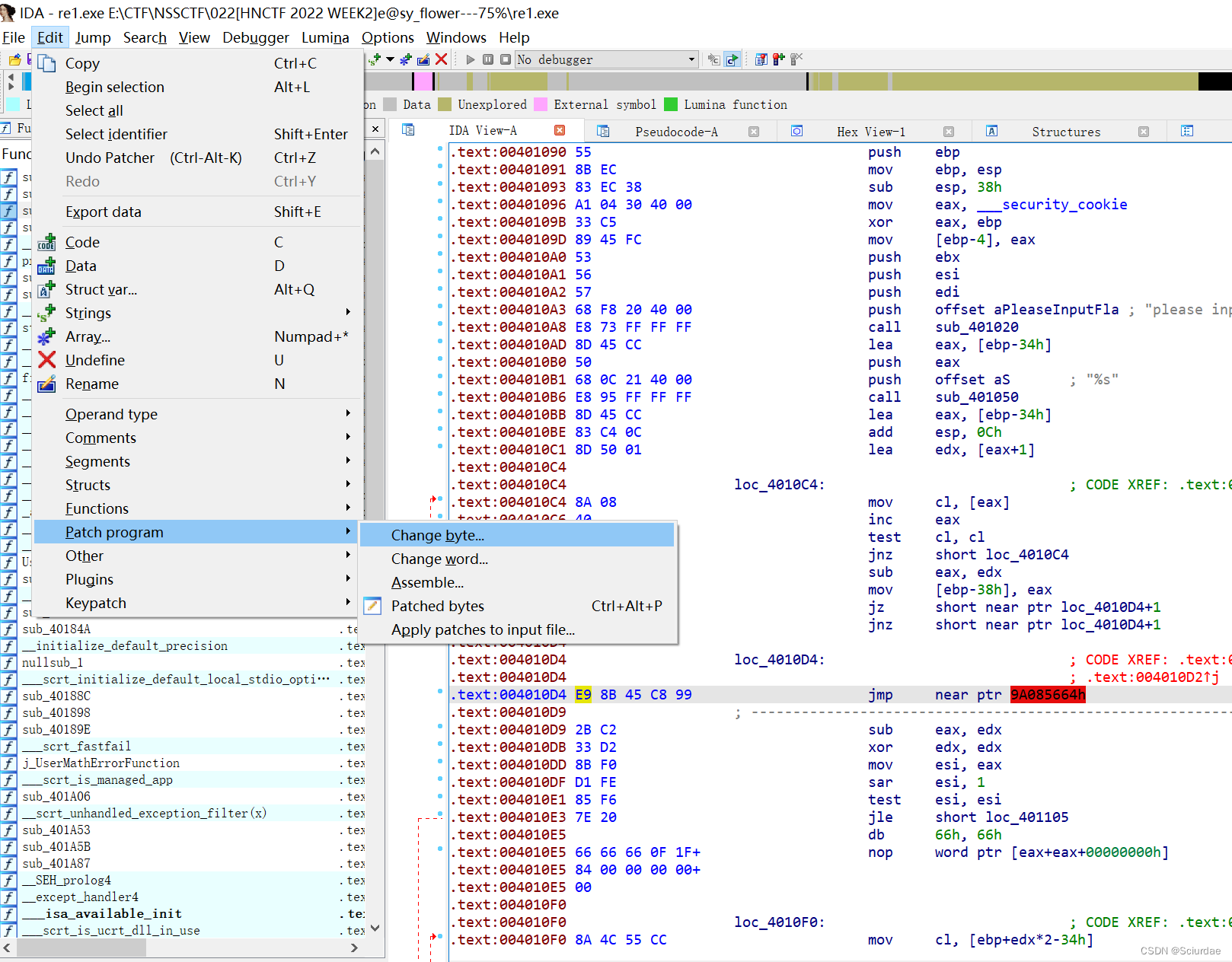
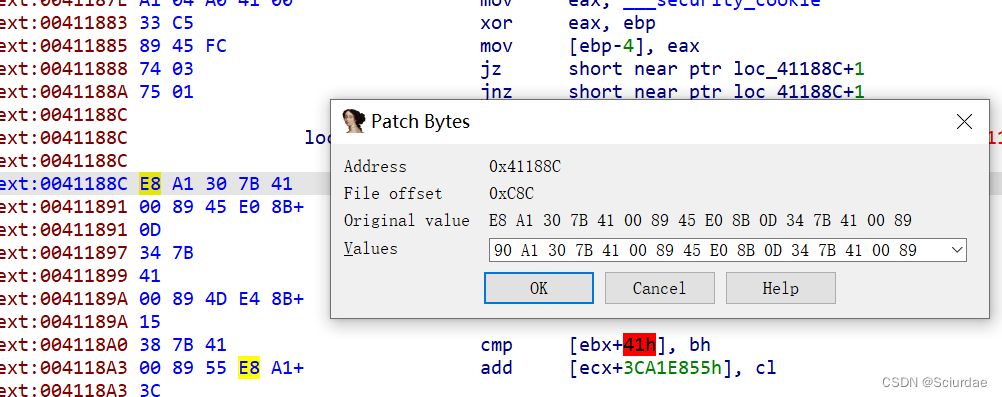
是jz和jnz构造的互补跳转花指令,还是先option设置打开opcode bytes的显示;将e8改为90(nop)
选中这一行,Edit-Patch program-Change bytes
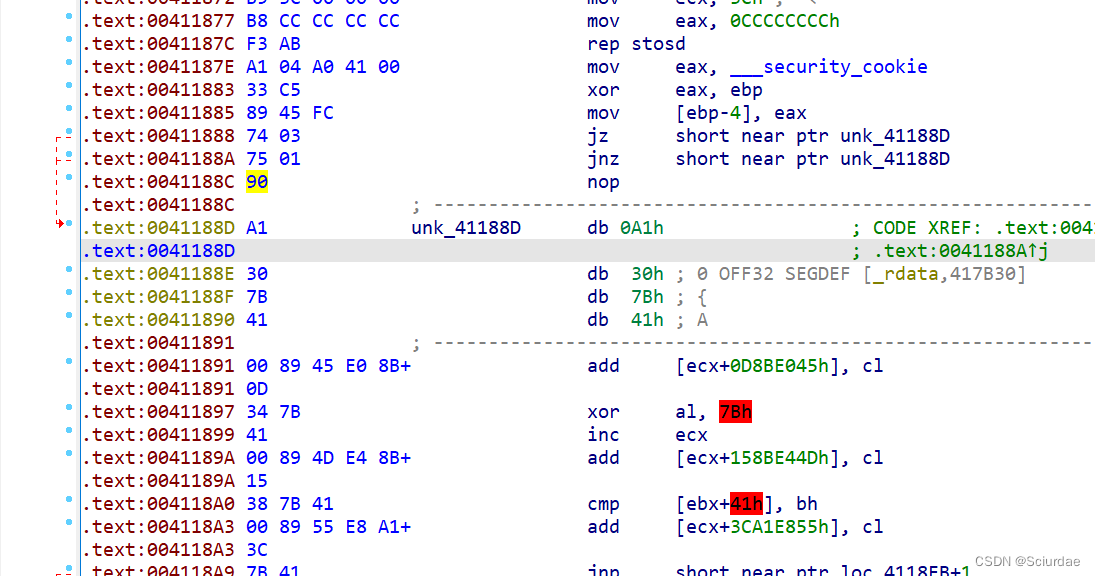
把第一个e9改为90就好,接着对main函数用P重新定义下,再F5反编译就🆗了
再点击黄色部分,一步一步按C转换为代码,直到没有黄色为止。
然后对main函数用p重定义一下
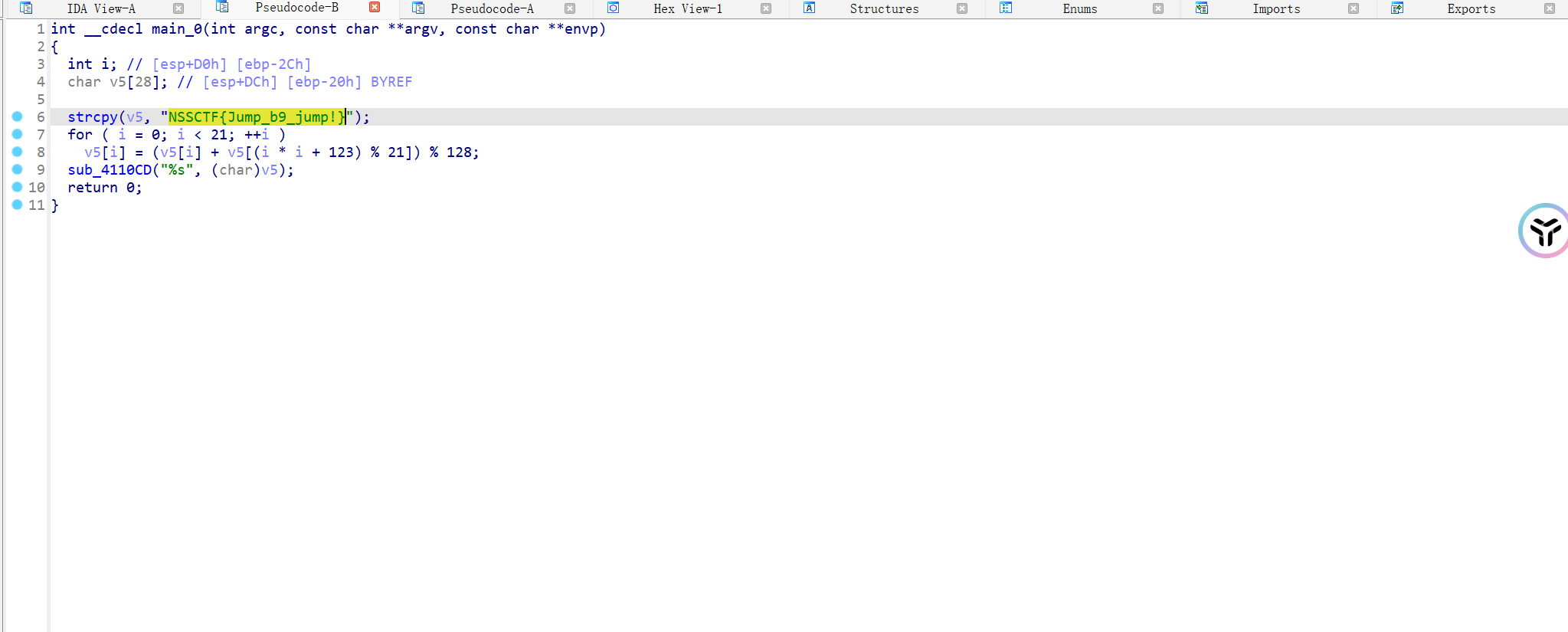
然后f5反编译就可以得到flag了
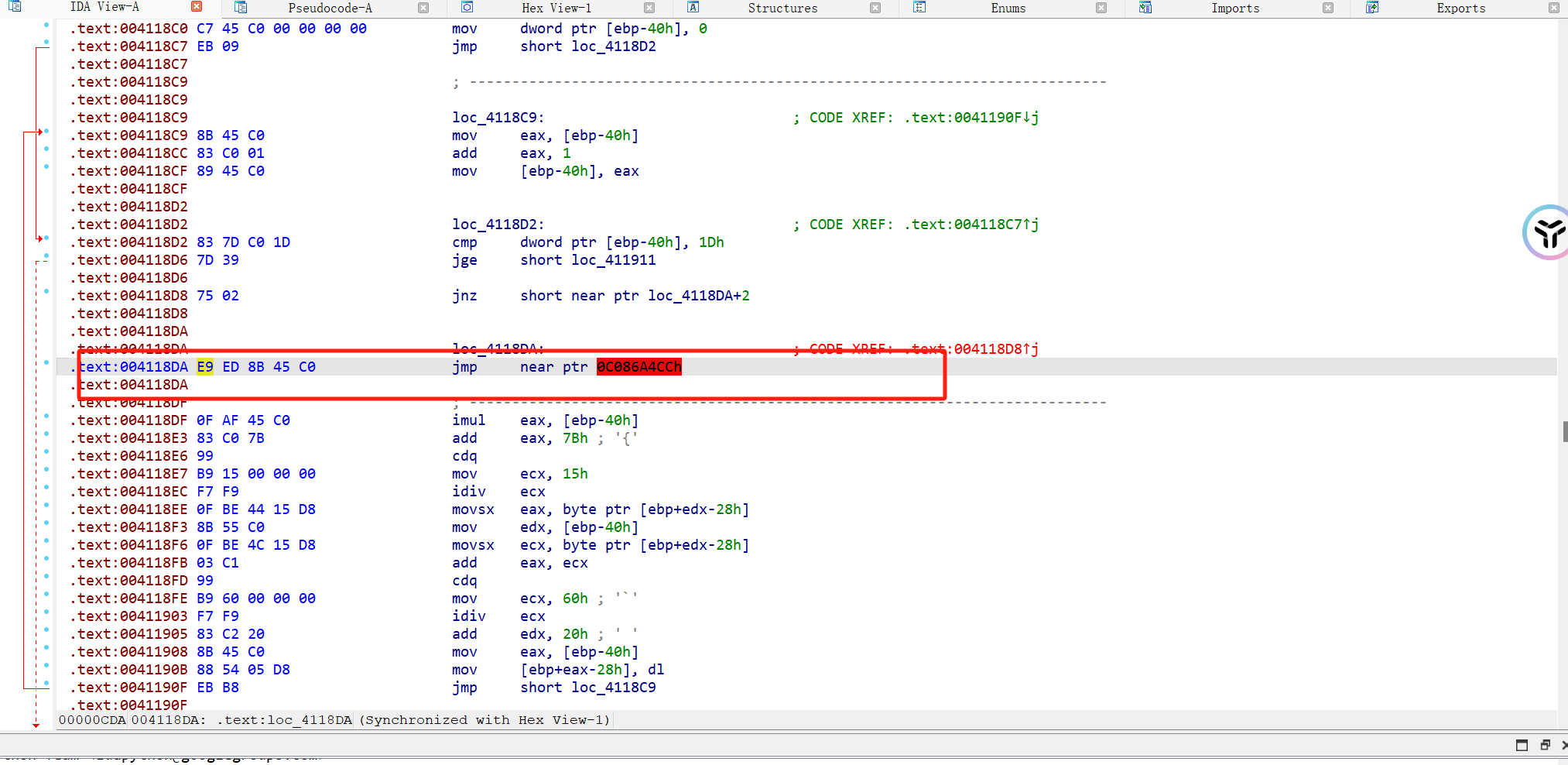
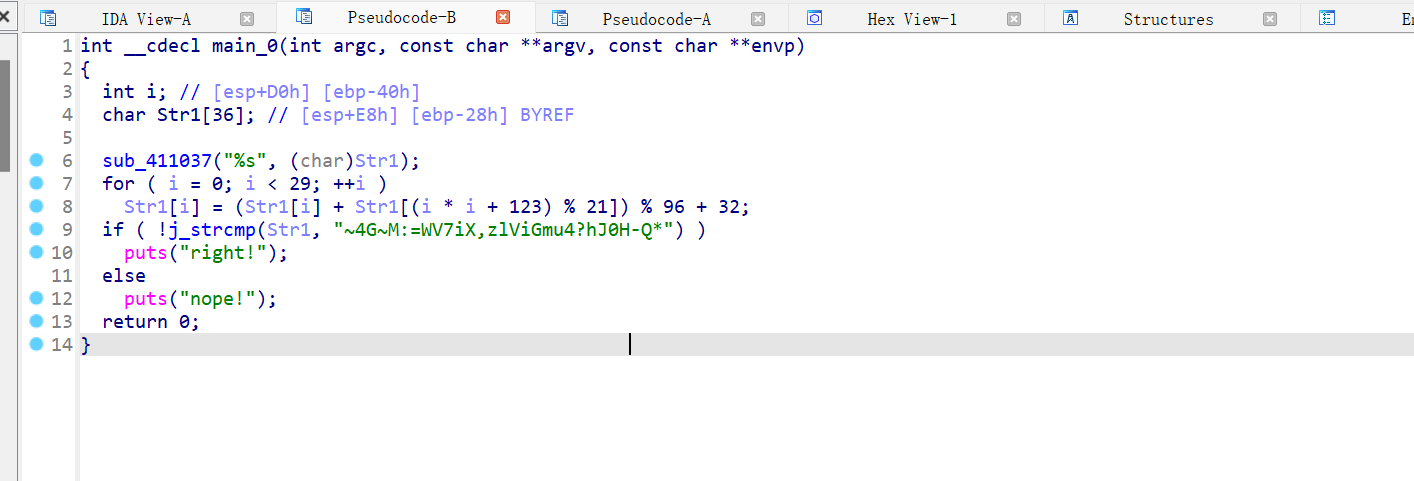
2、jump_by_jump_reverse
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def is_right (c ):return 32 <= ord (c) <= 125 def reverse_transformation ():list ("~4G~M:=WV7iX,zlViGmu4?hJ0H-Q*" )for i in range (28 , -1 , -1 ):ord (Str1[i]) - 32 ) - ord (Str1[(i * i + 123 ) % 21 ])while original_val < 32 :96 chr (original_val)return '' .join(Str1)if __name__ == '__main__' :print ("原始输入字符串:" , original_str)
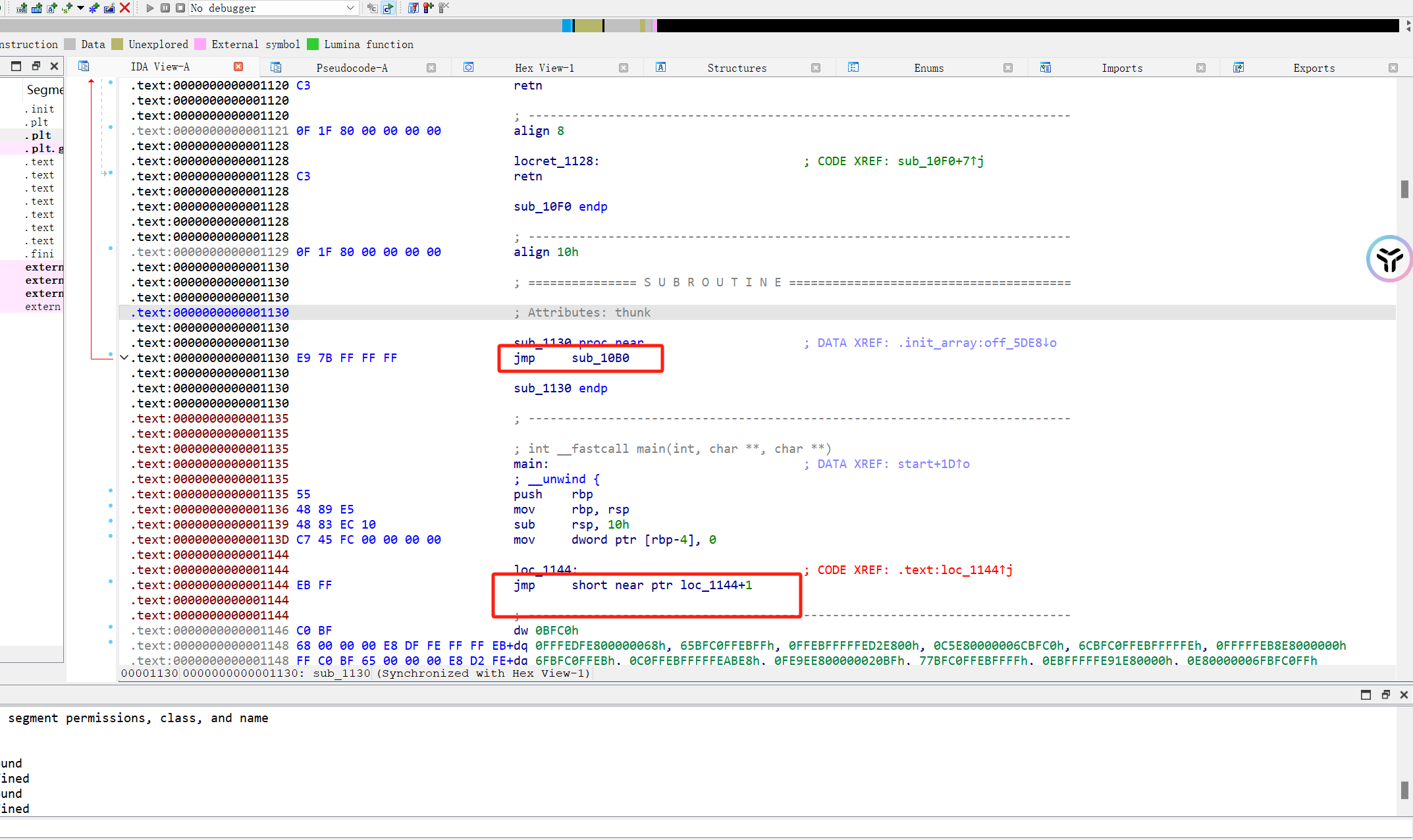
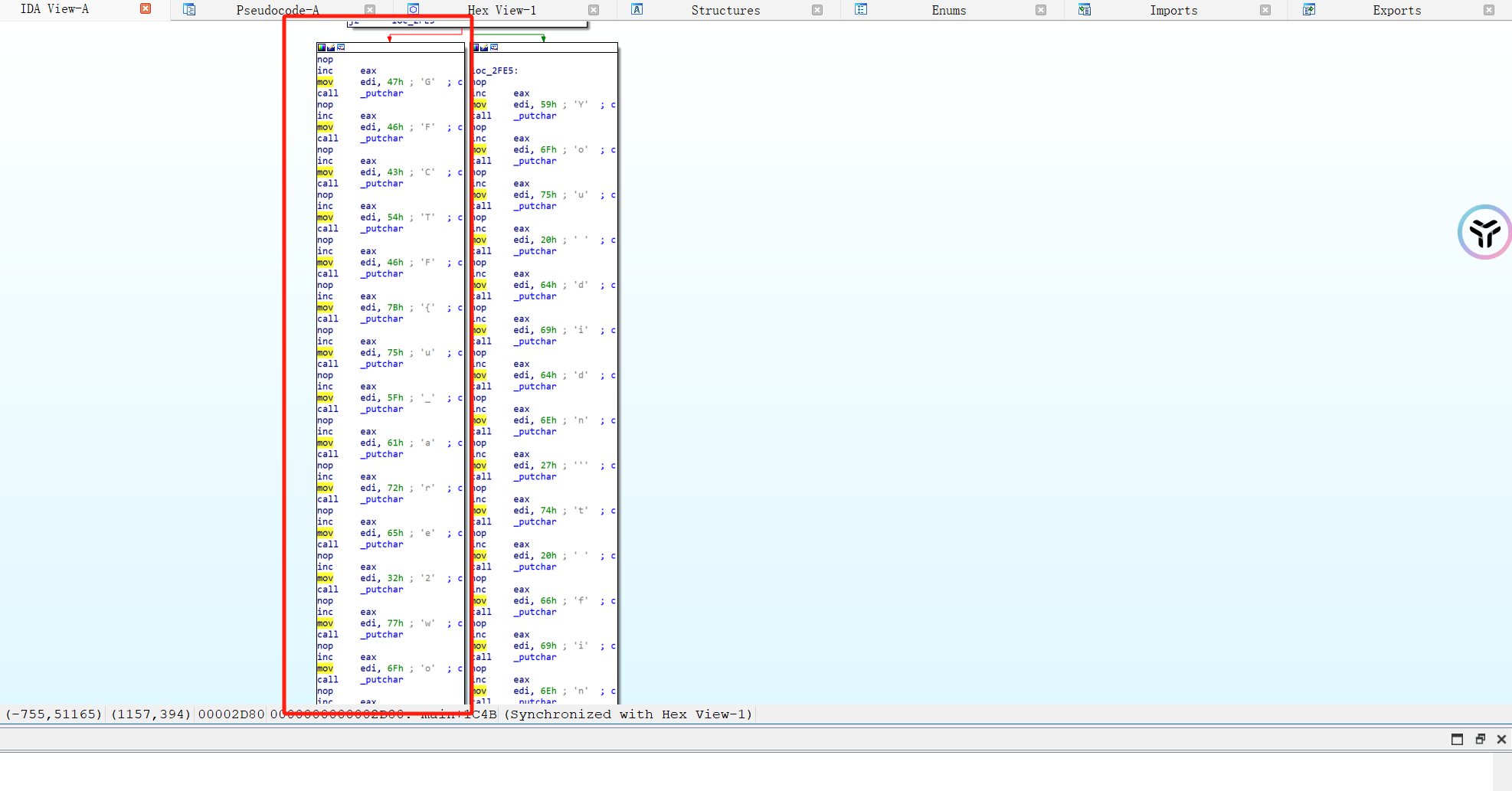
3、wordy IDA打开存在大量jmp跳转,导致程序无法正常编译,尝试将跳转nop掉
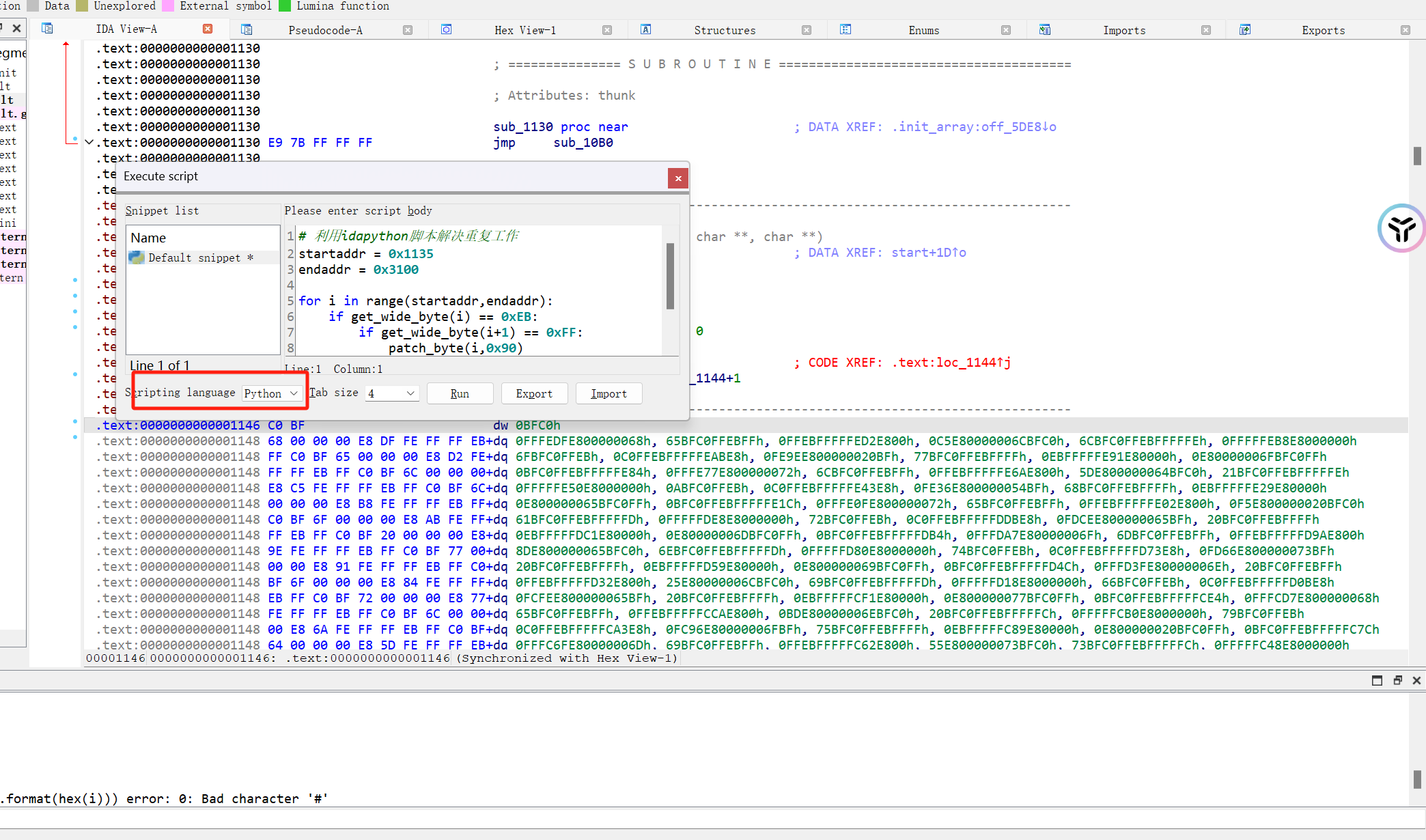
shift+F2添加exp
1 2 3 4 5 6 7 8 9 startaddr = 0 x1135endaddr = 0 x3100for i in range(startaddr,endaddr):if get_wide_byte(i) == 0 xEB:if get_wide_byte(i+1 ) == 0 xFF:patch_byte (i,0 x90)print ("[+] Addr {} is patched" .format(hex(i)))
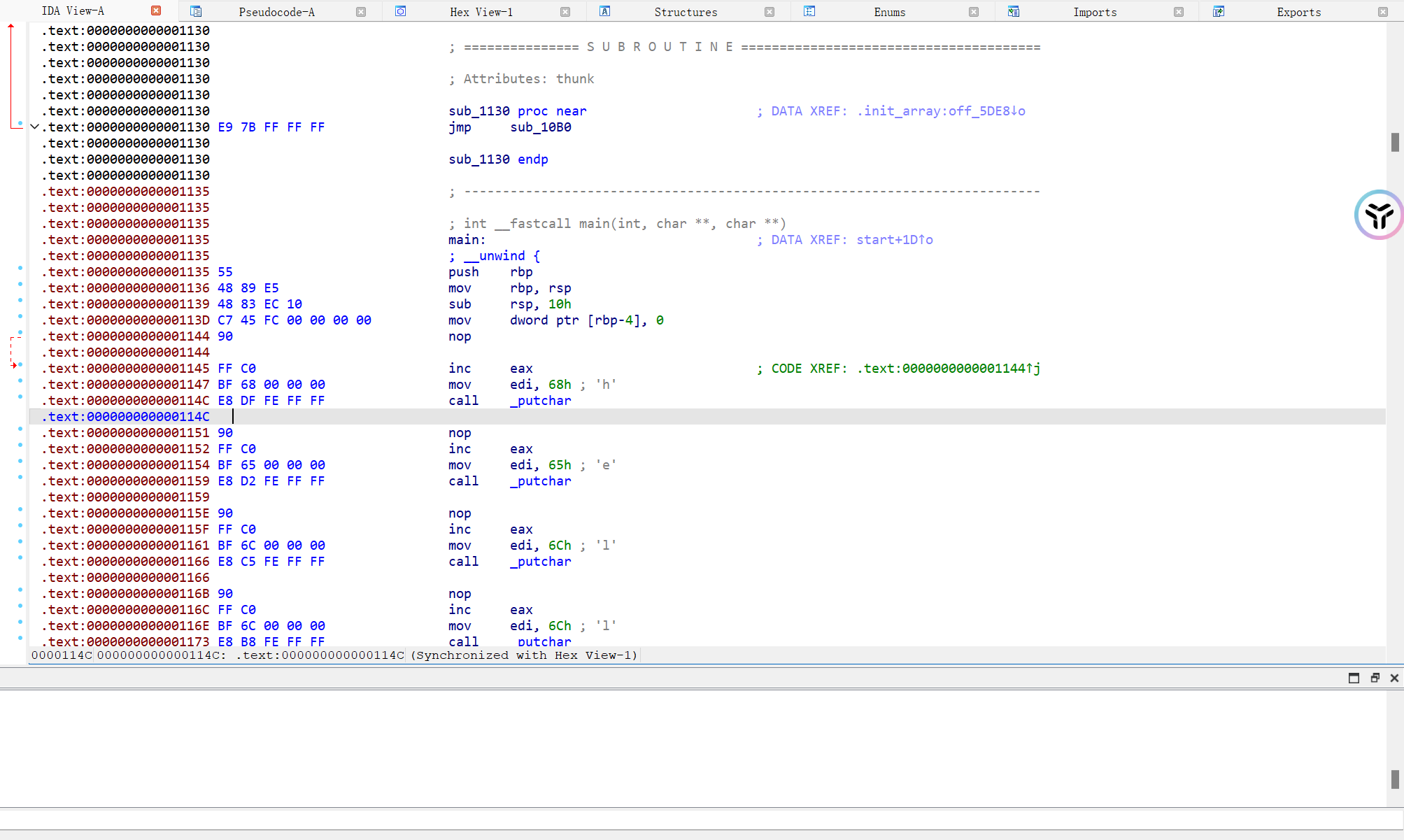
然后对main P一下,F5编译
如果没有脚本,建议空格去图里面看比较好
这里找到flag
附上大佬脚本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import idcprint ("-----" )hexStr ="EB FF C0 BF ?? 00 00 00 E8" '00' , '01' ).replace('??' , '00' ))'??' , '00' ))signs =ida_bytes.BIN_SEARCH_FORWARD| ida_bytes.BIN_SEARCH_NOBREAK| ida_byteprint (bMask,bPattern)begin_addr =0x1135end_addr =0x3100s ="" while begin_addr<end_addr:ea =ida_bytes.bin_search(begin_addr,end_addr,bPattern,bMask,1,signs)if ea == ida_idaapi.BADADDR:else :begin_addr =ea+8print (s)
非预期 打开16进制转存储视图,可以看到flag(hex_dump)
GFCTF{u_are2wordy}
4、e@sy_flower
放入32位ida
将E9改成90,保存一下发编译即可
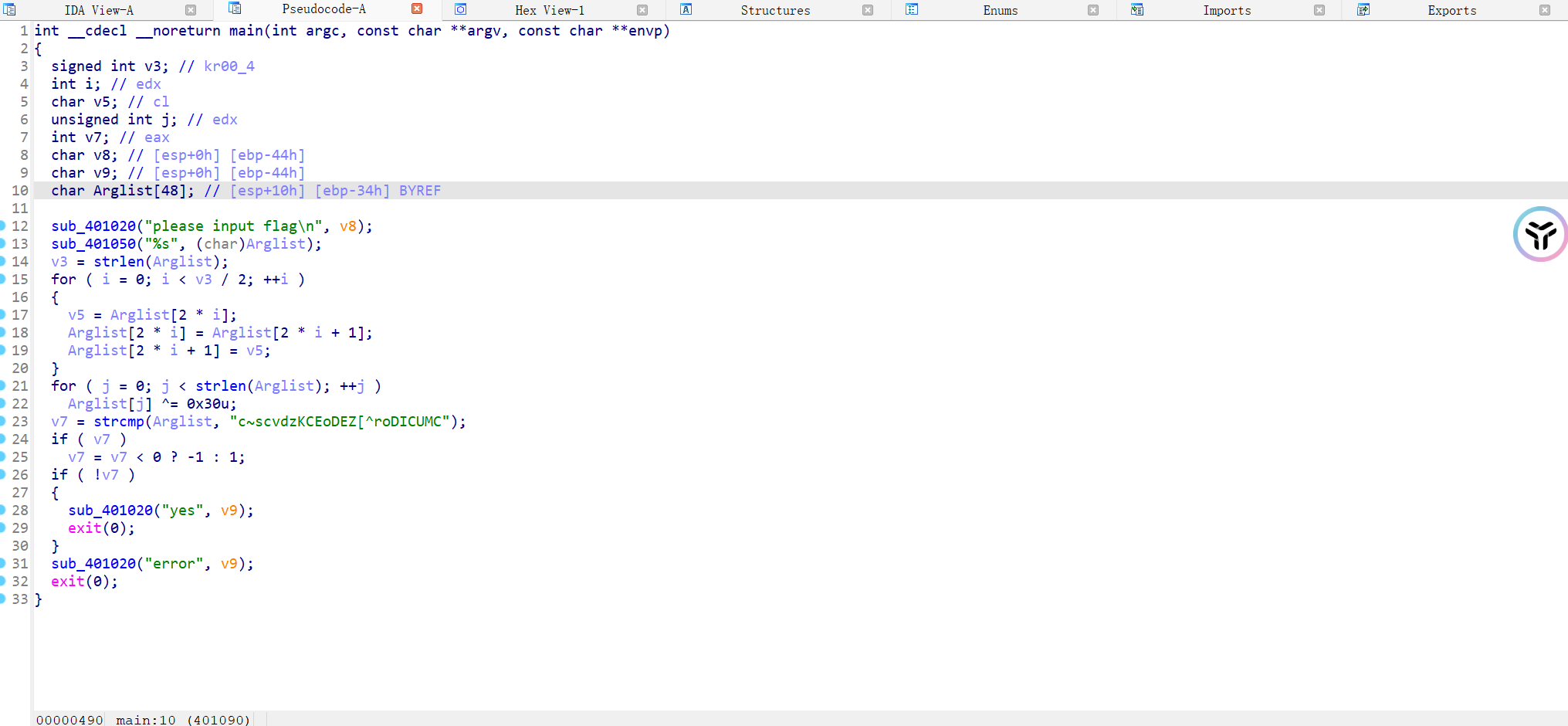
简单逆向一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 a = list('c~scvdzKCEoDEZ[^roDICUMC' )for i in range(len (a )):a [i] = chr(ord(a [i]) ^ 0x30 )"After XOR operation:" , '' .join(a ))for i in range(len (a )a [i * 2 ]a [i * 2 ] = a [i * 2 + 1 ]a [i * 2 + 1 ] = tmp"After swapping:" , '' .join(a ))
1 2 3 4 5 6 7 8 9 a=list ('c~scvdzKCEoDEZ[^roDICUMC' )for i in range (len (a)):a [i] =chr (ord (a [i] )^0 x30)print (a,end='\n' ) for i in range (len (a)a [i*2] a [i*2] =a [i*2+1] a [i*2+1] =tmpprint ('' .join(a)
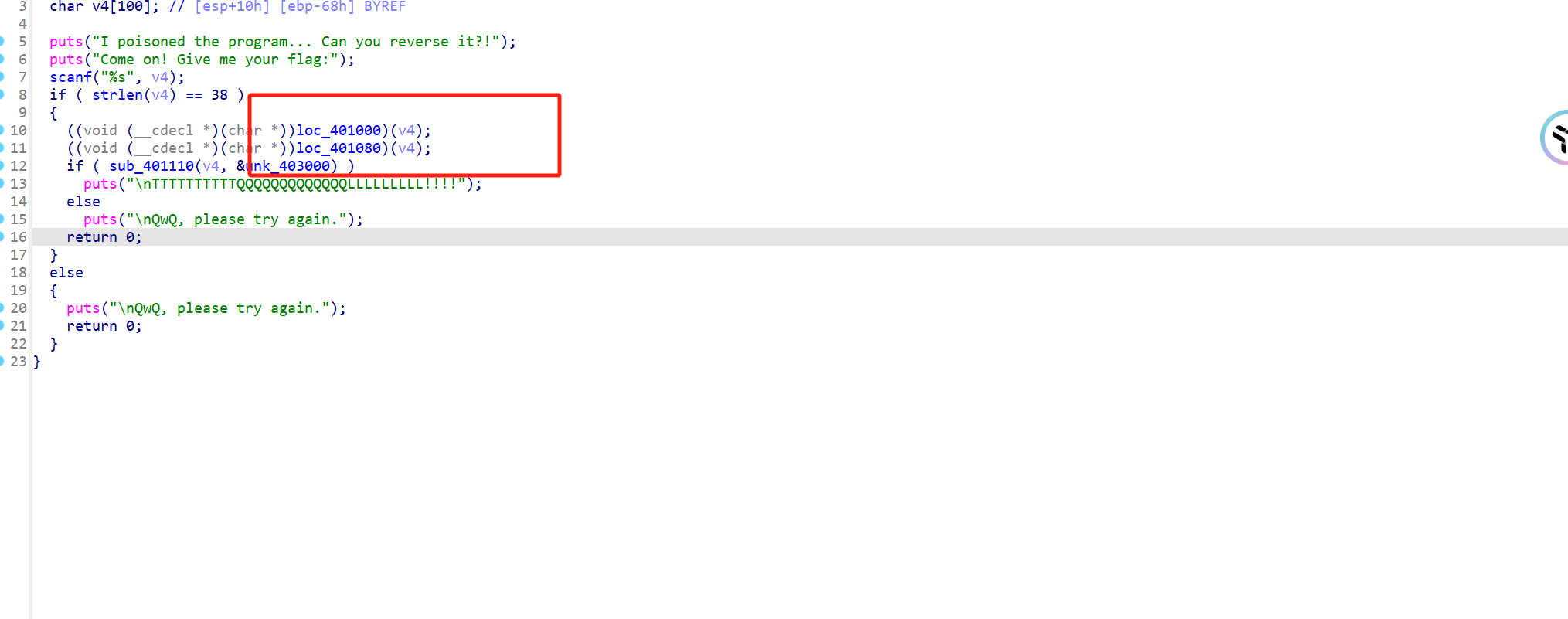
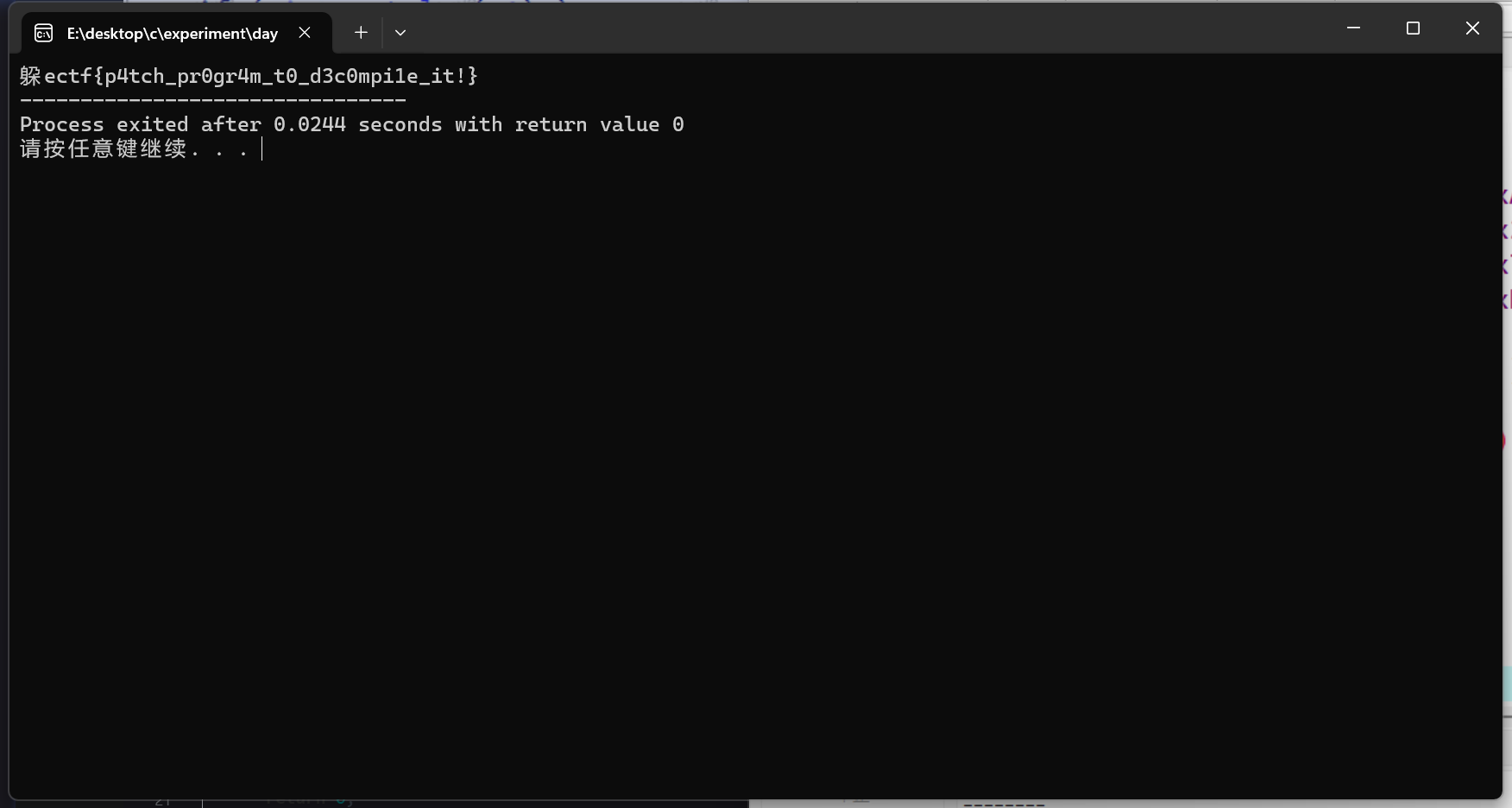
5、chicken_soup
放入32位
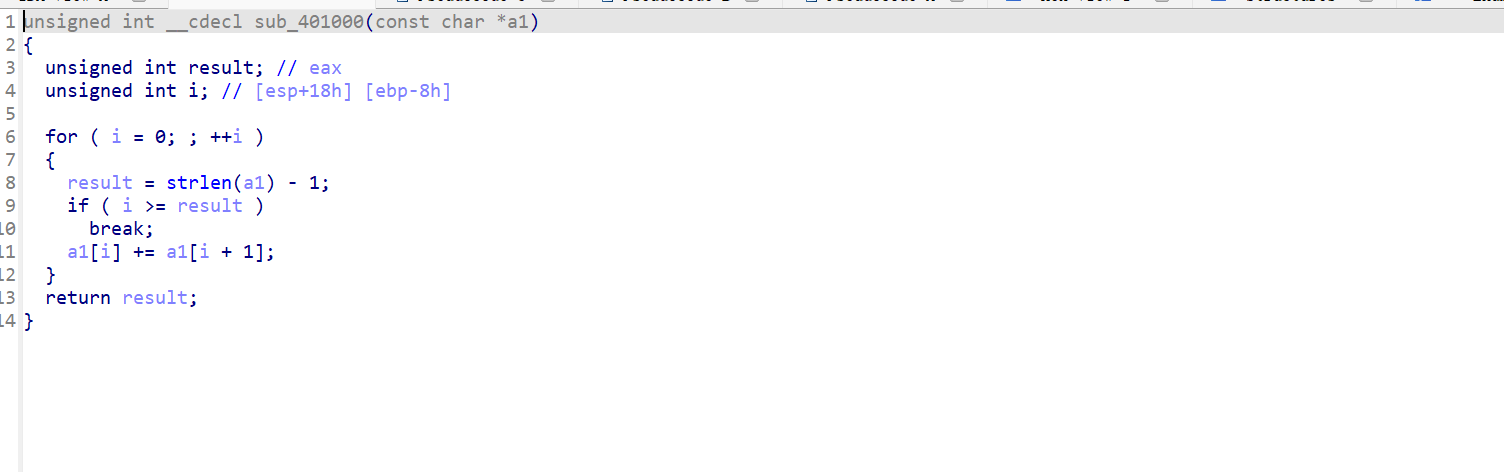
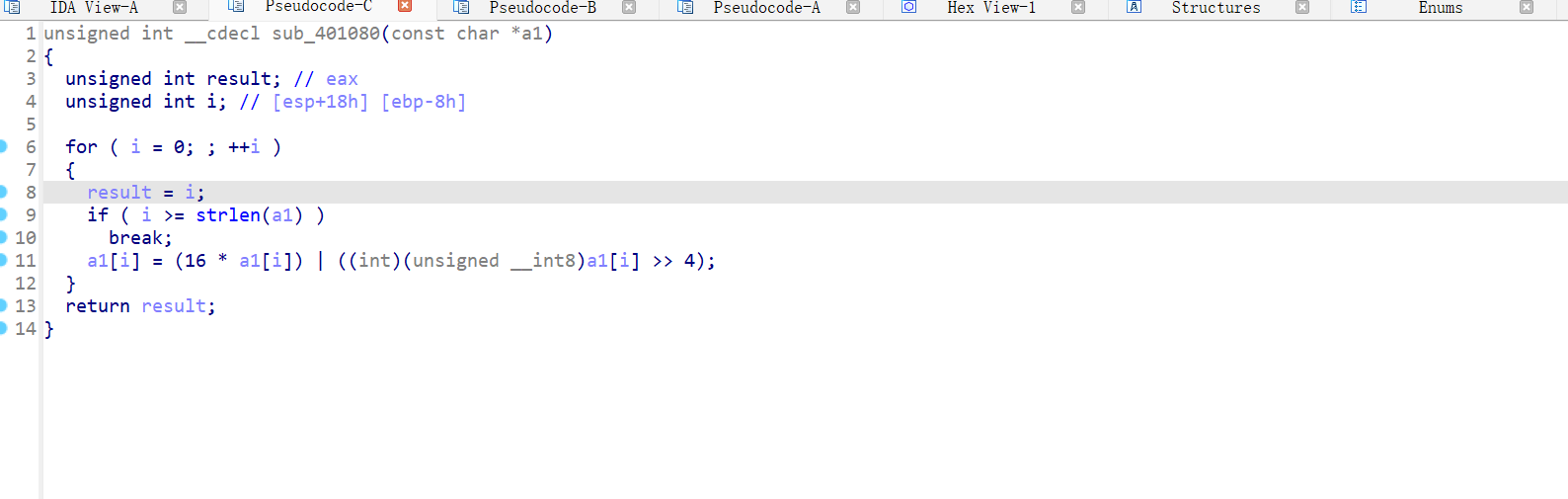
看到两个对v4的加密函数
跟进去nop一下
按p创建函数,C一下黄色的汇编代码,然后F5反编译
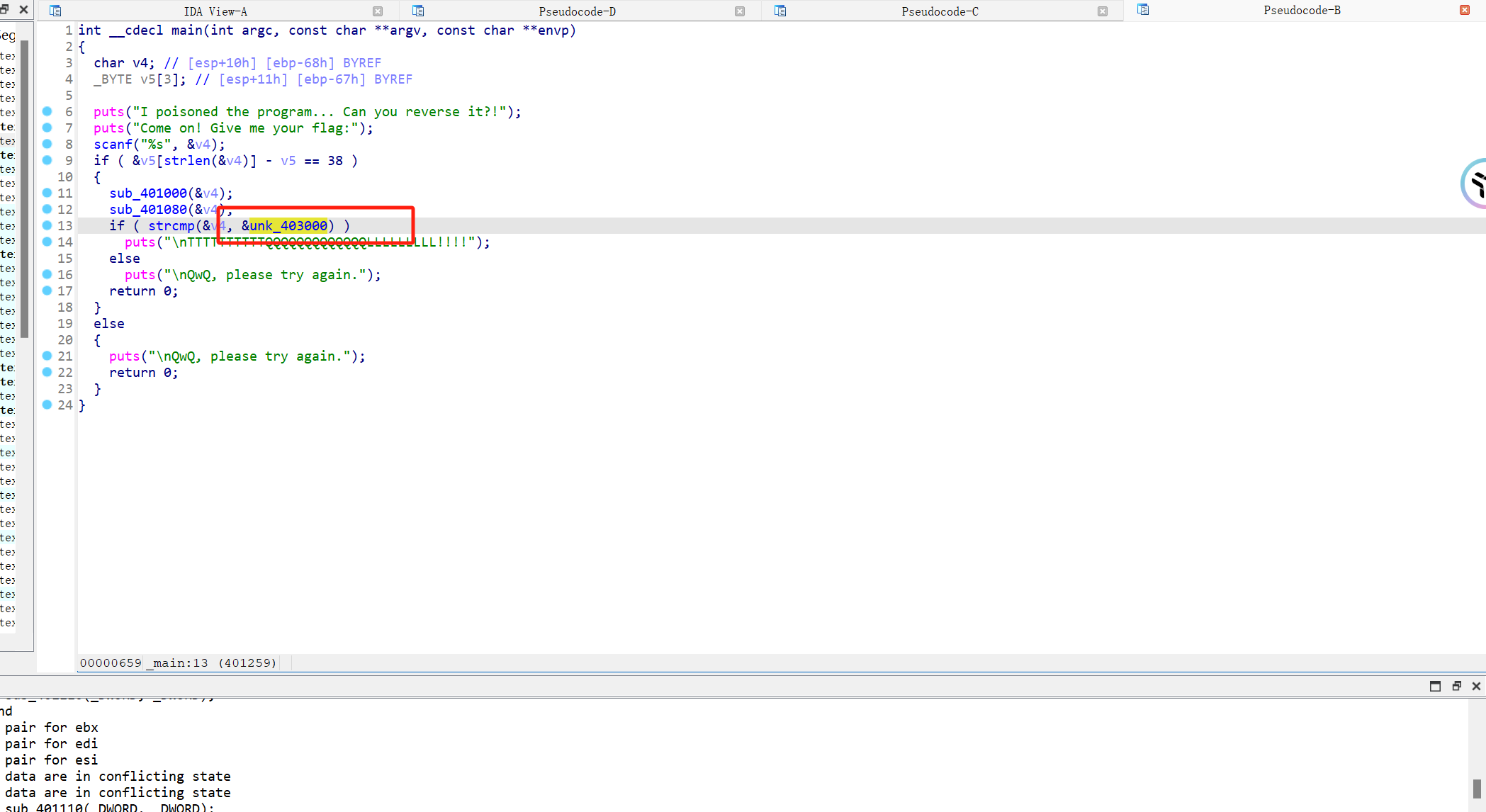
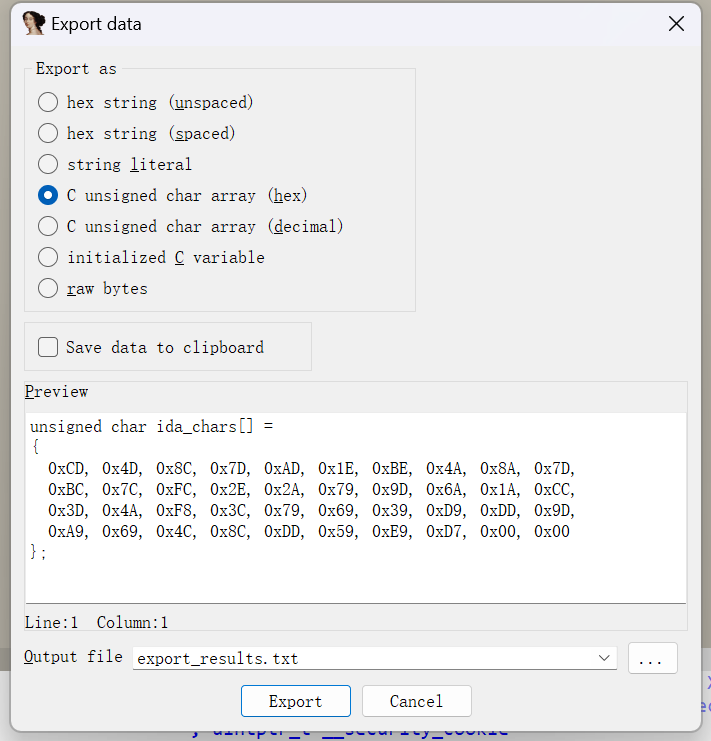
找到比较数据源
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include<stdio. h>int main()0xCD , 0x4D , 0x8C , 0x7D , 0xAD , 0x1E , 0xBE , 0x4A , 0x8A , 0x7D ,0xBC , 0x7C , 0xFC , 0x2E , 0x2A , 0x79 , 0x9D , 0x6A , 0x1A , 0xCC ,0x3D , 0x4A , 0xF8 , 0x3C , 0x79 , 0x69 , 0x39 , 0xD9 , 0xDD , 0x9D ,0xA9 , 0x69 , 0x4C , 0x8C , 0xDD , 0x59 , 0xE9 , 0xD7 int i = 0 16 * a1[i]) | (a1[i] >> 4 )int j=36 1 ]int i=0 "%c" ,a1[i])0
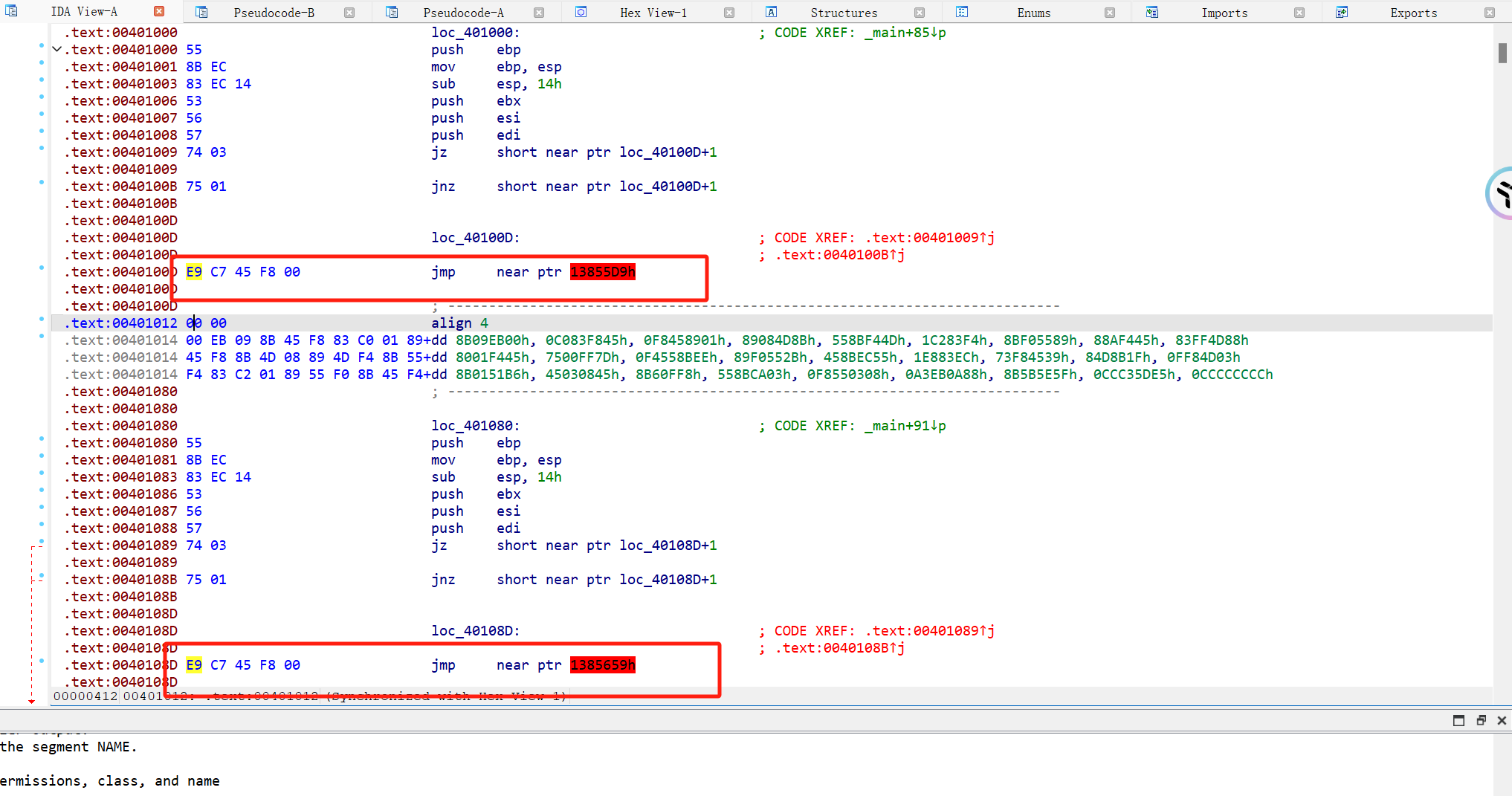
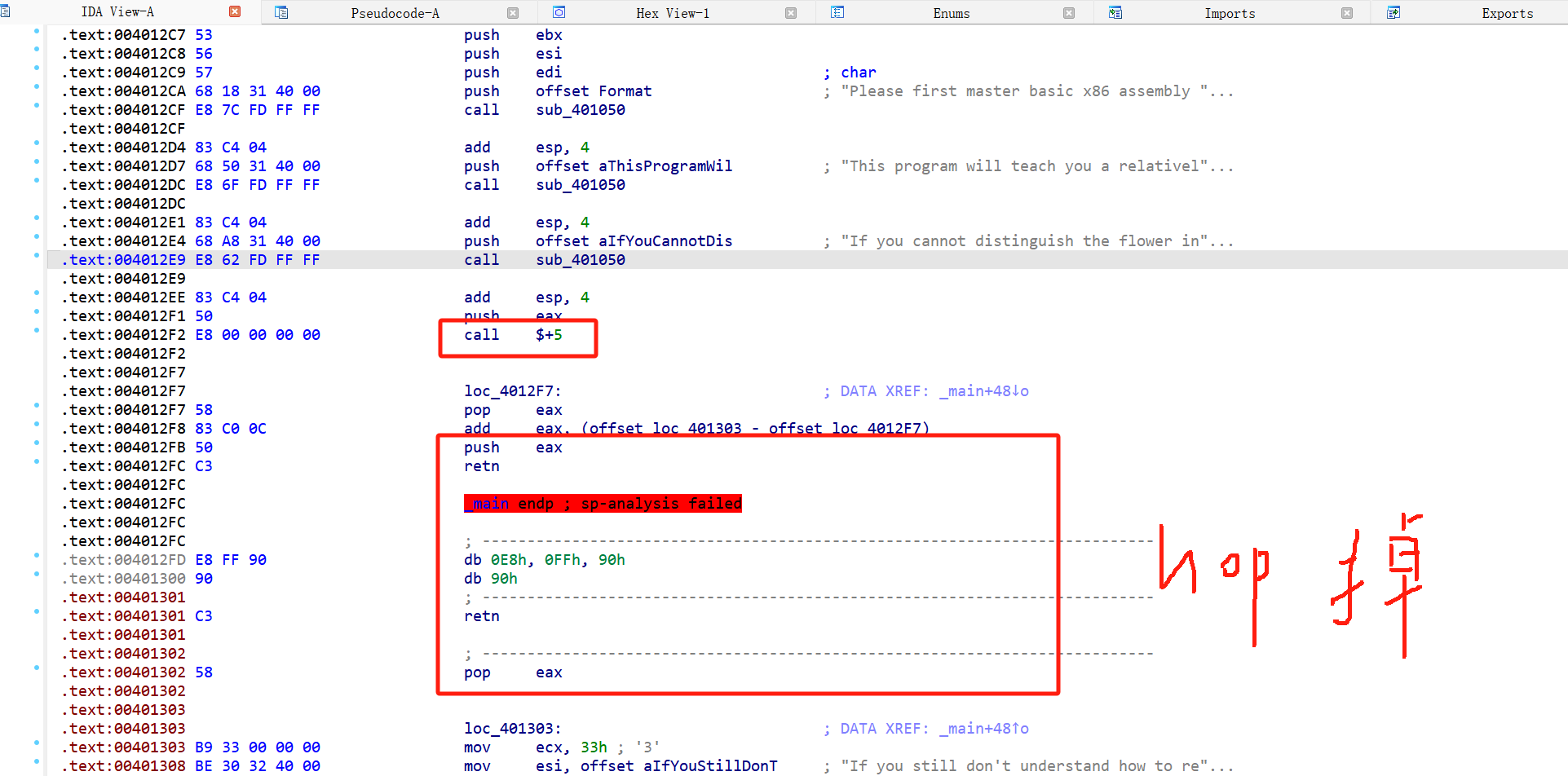
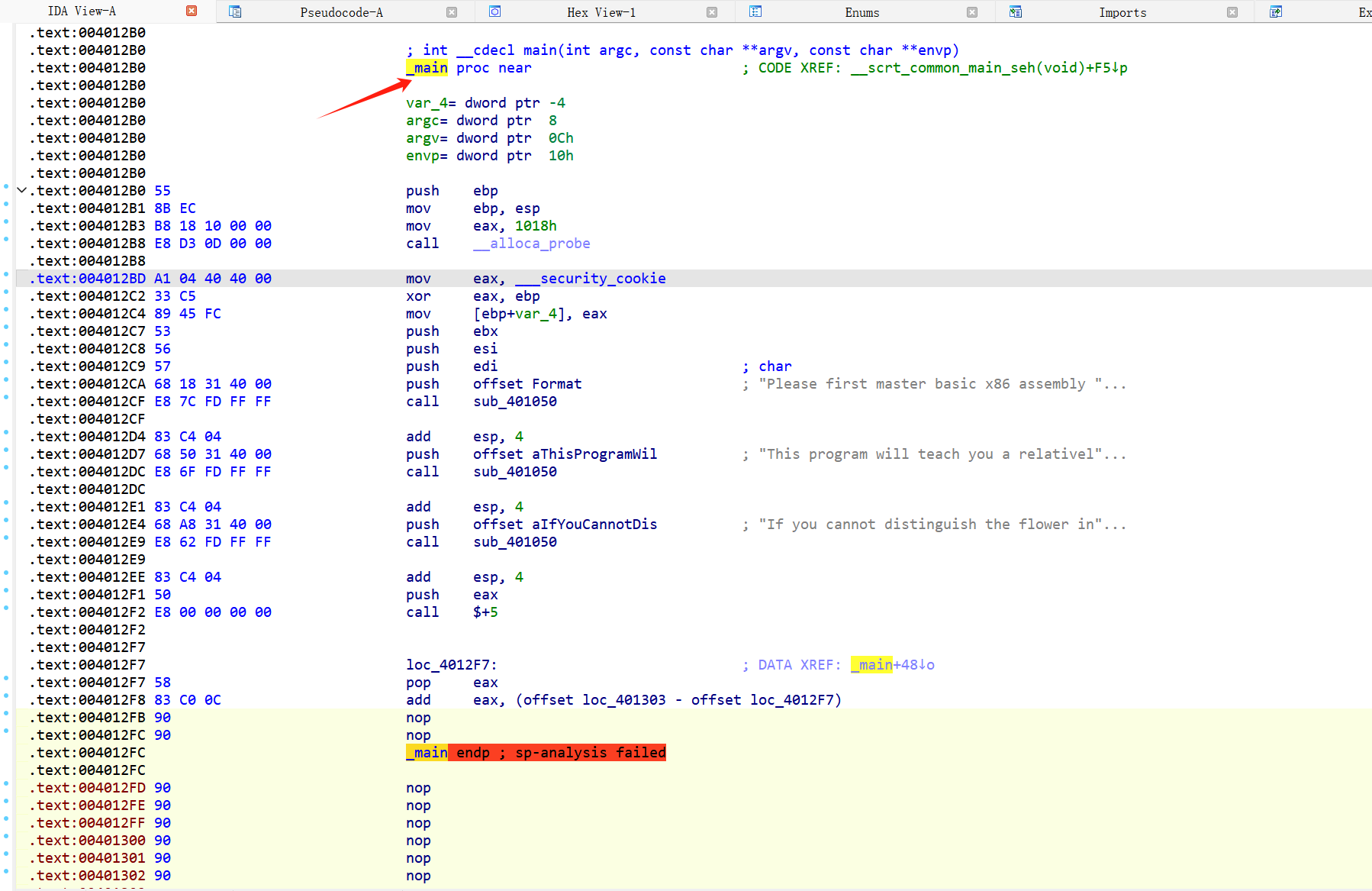
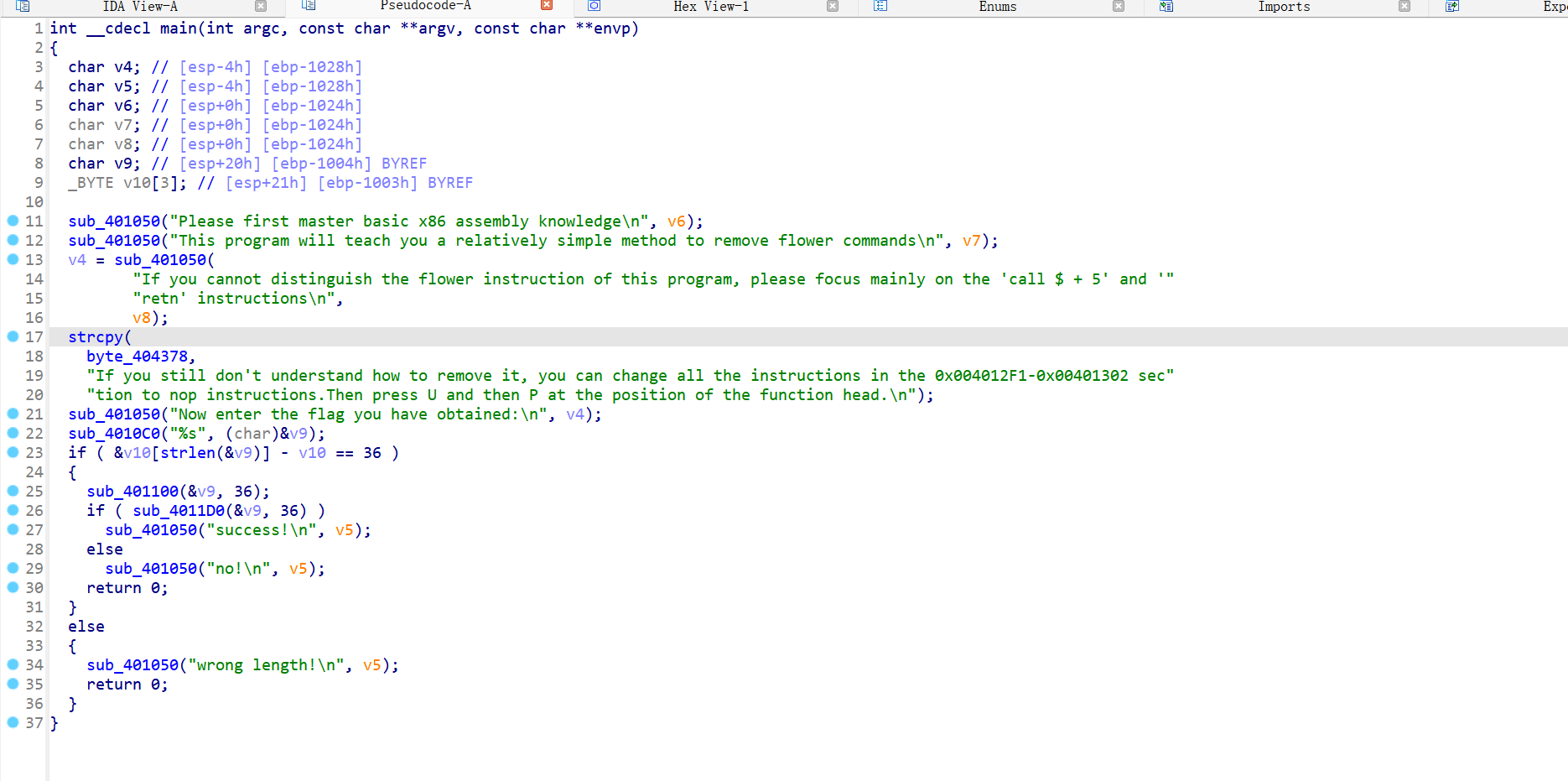
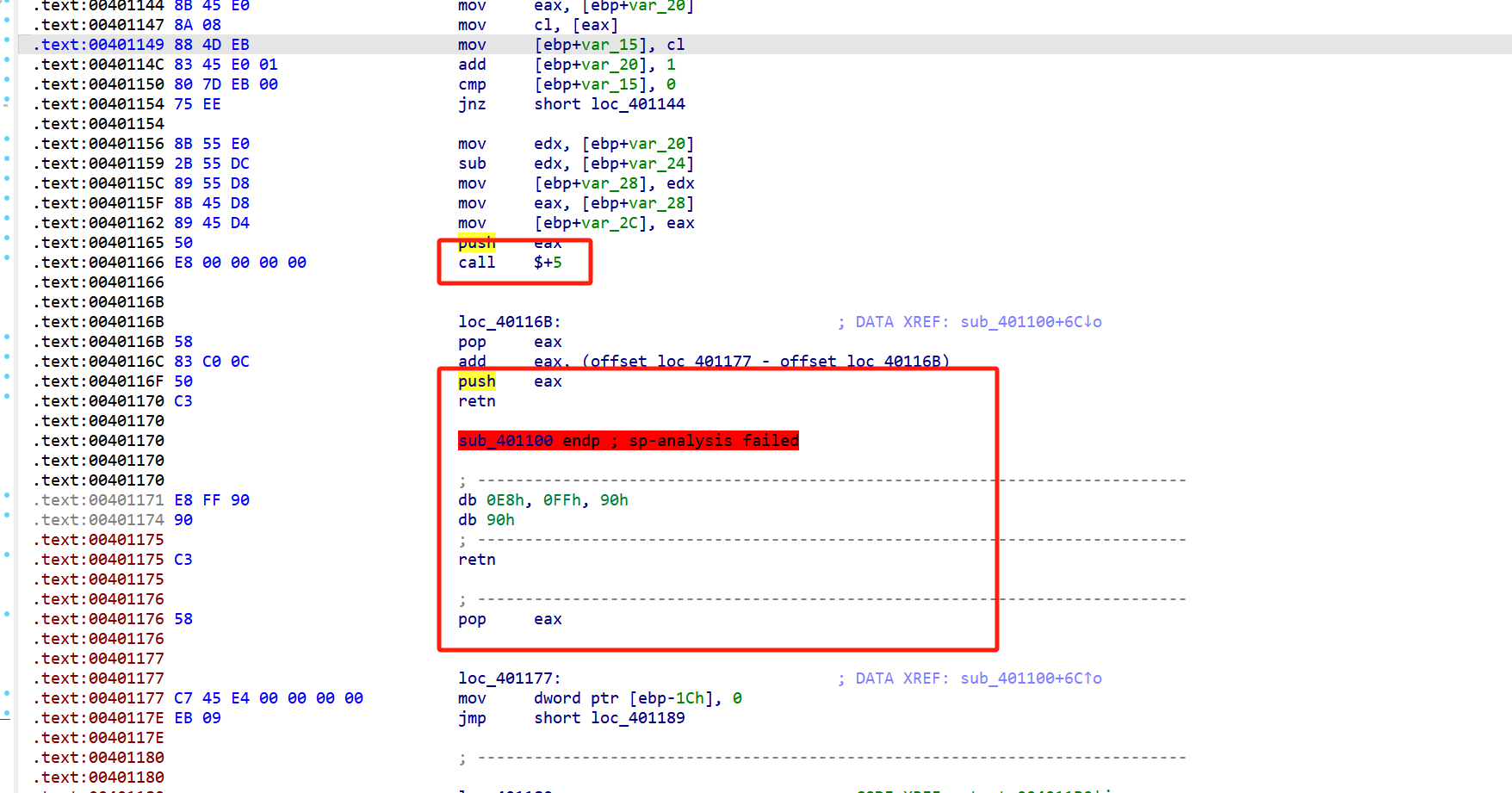
例题ret call$5 dirty_flower 第一个异常,call $+5,看完以后,发现前面的push eax,,后面的retn, 跟着pop eax,从push eax 到pop eax,直接改成nop ,然后回到上面的main ,用U改成未定义,在用P重新生成就可以了
就可以反编译了,
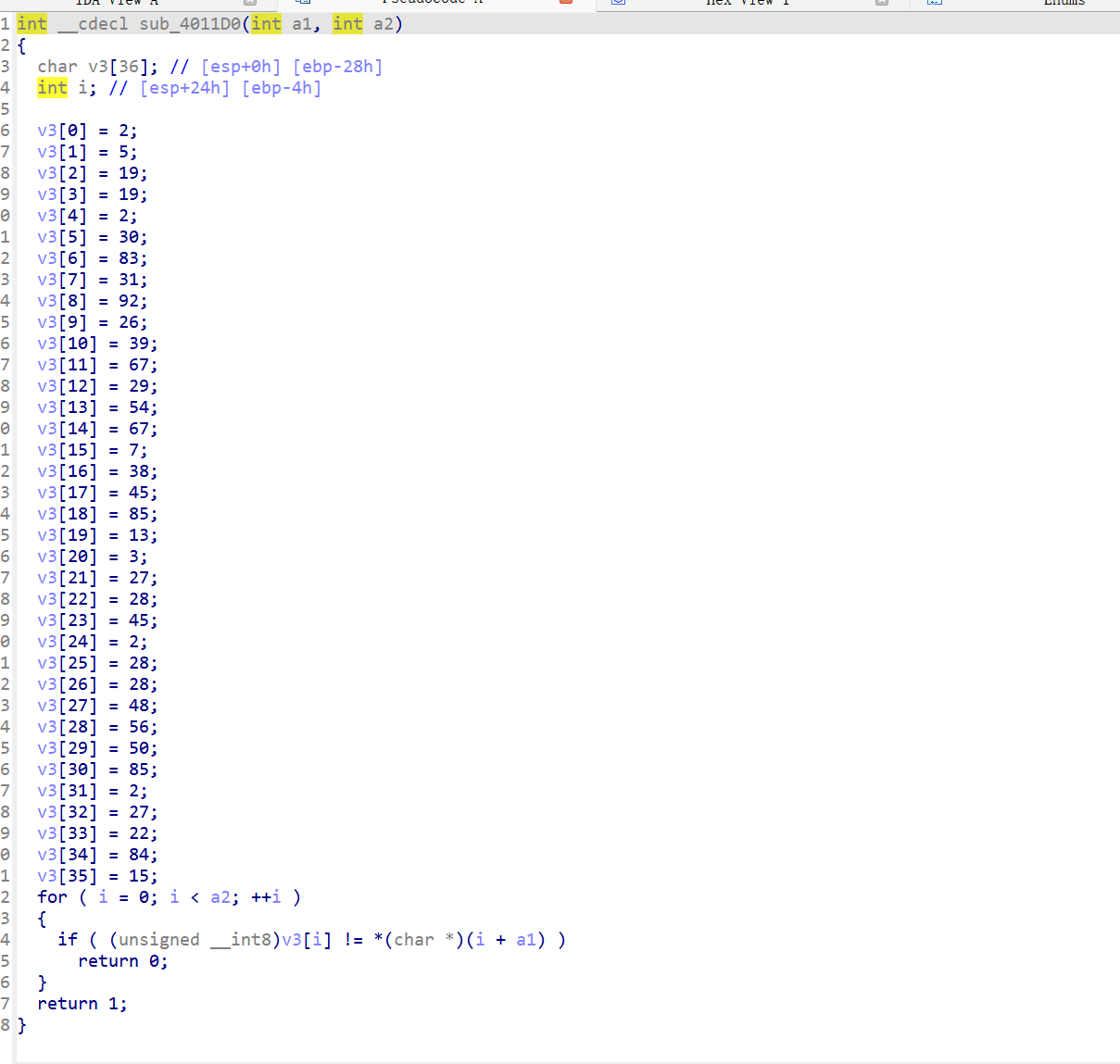
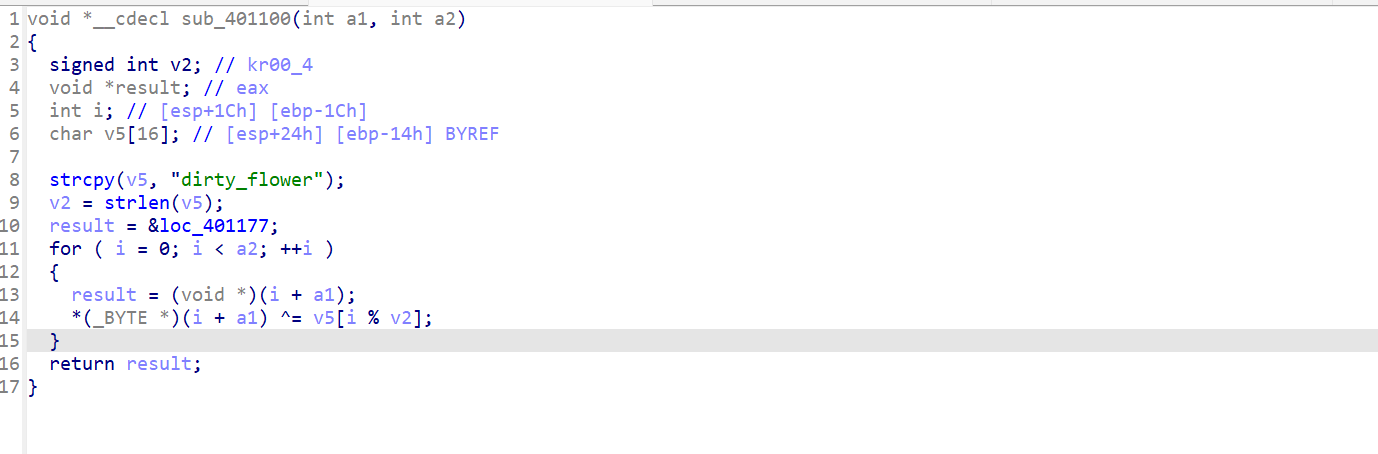
下面这个函数也是一样的,nop后去上面找到该函数,u,p
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include<stdio.h>"dirty_flower" ;36 ]={0 };0 ] = 2 ;1 ] = 5 ;2 ] = 19 ;3 ] = 19 ;4 ] = 2 ;5 ] = 30 ;6 ] = 83 ;7 ] = 31 ;8 ] = 92 ;9 ] = 26 ;10 ] = 39 ;11 ] = 67 ;12 ] = 29 ;13 ] = 54 ;14 ] = 67 ;15 ] = 7 ;16 ] = 38 ;17 ] = 45 ;18 ] = 85 ;19 ] = 13 ;20 ] = 3 ;21 ] = 27 ;22 ] = 28 ;23 ] = 45 ;24 ] = 2 ;25 ] = 28 ;26 ] = 28 ;27 ] = 48 ;28 ] = 56 ;29 ] = 50 ;30 ] = 85 ;31 ] = 2 ;32 ] = 27 ;33 ] = 22 ;34 ] = 84 ;35 ] = 15 ;0 ;i<36 ;i++)"%c" ,v3[i]);0 ;





 exp
exp